-
“Yes…but.” — Saving ideas in their infancy
“Yes…but.” — Saving ideas in their infancy
Photo by Mika Baumeister on Unsplash Ideas are fragile. In an idea’s infancy, it doesn’t take much to do irreparable damage to it. This is why how we approach new ideas and the language used during an idea’s infancy is so important.
One of the biggest killers of an idea is the tendency to front load the idea conversation with all the reasons an idea can’t succeed.
“It won’t work. We wouldn’t be able to know ahead of time all the inputs necessary.”
“It won’t work. Processing time would take too long.”
“It won’t work. These two systems can’t talk to each other.”
All of these are examples of idea killers. But they’re only idea killers because of the wording and the way we deliver the objection. Imagine if instead, we approached the idea from a perspective of curiosity and a commitment to the idea. Let’s add a few simple words to these idea killers and see how they seem afterwards.
“Yes, but we’ll have to keep processing time to under an hour.”
“Yes, but we’ll need to figure out how to anticipate all the inputs.”
“Yes, but we’ll need to figure out how to communicate between these two systems.”
By just changing the way we speak and challenge the idea we’ve done a couple of things.
- We’ve noted the potential problem without killing the idea.
- We’ve aligned ourselves with the idea giver as an ally. We’re now working towards a solution together.
Being able to align yourself with the solution puts you in a completely different mindset in terms of how you approach a problem. It doesn’t mean that the problems presented aren’t real and they very well might be insurmountable. But now you’ve explored the idea, supported the idea giver and most likely have come up with alternative methods that partially solve the problem.
The “Yes, but” approach is increasingly more important in remote working environments. Text based conversations operate on a different level of social interaction. Text based conversations are devoid of the non-verbal communication we often give, even subconsciously.
Even though our texts are devoid of these non-verbal cues, our minds haven’t adapted to the fact that we’re not sending them. Text based messages go out devoid of the signals that might soften your communication style. Instead the recipient is stuck, interpreting your message with energy you may or may not have intended. This is particularly true of messages around ideas.
If a person is already timid about sharing their idea, any critical comments about the idea will be interpreted in the worst light. The simple action of “Yes, but” can help to align yourself and provide support for your team member while still bringing up real world challenges.
The literal worlds “Yes but,” don’t have to be used. The key is to do the following:
- Acknowledge and validate the idea.
- Address the problem as a solvable hurdle to the idea.
- Word things so that it is clear you plan on collaborating on the solution for the idea.
Just these three steps can help save a lot of ideas and help them get out of their infancy and into full-fledged solutions to help you and your team.
-
Troubleshooting Computers Made Me a Better Patient
Troubleshooting Computers Made Me a Better Patient
Unfortunately, I’ve spent the last few days hospitalized. It doesn’t appear to be serious, the type of mundane virus or bacteria that can wreak havoc on the immunocompromised. But my stay here has given me an opportunity to watch the troubleshooting process in a different field. The art of troubleshooting isn’t an innate skill. It’s one that crafts-people develop over time. They can think about the process, they can articulate how they go about it and their process sets up an easy way to refute bad theories or continue investigating theories with a lead.
I’ve always had this issue accepting that where I work is a smaller representation of society as a whole. “Not everyone at work is a great troubleshooter, but that’s not the case in medicine!” Unfortunately, I am wrong. But if you can abstract your troubleshooting process, I assure you it can be applied to any field. Anywhere.
Systems are Complicated, Break Them Up
If you’ve ever had to troubleshoot a large complex system, I think one of the things you find out is that it’s almost impossible to do. What you don’t consider is that with enough examination, any system is likely large and complex. It’s the distance you’re viewing it from that makes its complexity visible.
When you come into a problem, the first thing you have to think about is how that problem breaks up into different spaces or components. Where are the hand-off points and at what moment can we determine where the cause lies. Sometimes you do this innately when you’re well-versed with a system, but when you get into systems you don’t know you often ditch this specific skill. For example, when you’re troubleshooting your web browsing what are the things you check for?
- Am I connected to the Internet? Meaning, can I get anywhere on the web?
This makes you divide the problem in half. If you can’t get to the Internet at all, you’re now thinking that your focus should be on things that are necessary beforeconnecting to the Internet. You might do ask questions like:
- Can I connect to other machines on my local network?
- Can I resolve DNS hostnames?
- Is my router working?
Answering these questions not only moves you steps closer to figuring out the answer, but it also helps you eliminate other theories. Your friend says “I can’t get to that website either!” That’s fine. But you can’t get to any website. So obviously you and your friend have two different issues. Once you solve your issue with Internet connectivity, you might be on the same page, but for now you’ve got your own sets of problems.
It also helps you to gauge how many problems you might be dealing with. In addition to the Internet connectivity problem, let’s say you have an issue launching Power Point. It throws a weird cryptic error.
- Is it possible that the Internet error is causing this?
- Have you seen this same error before with Internet connectivity?
This helps set the stage for future questions about symptoms that are happening at the same time but might have different sources. It might be easy to conclude “Fix the Internet and PowerPoint should start working.” But if you know that PowerPoint isn’t dependent on the Internet, then it could be a bad idea to tie these things together.
After you break them up solve the individual problems
Once you break the systems up, you might have a bunch of separate problems. If you’re well-versed in the system, you might be able to separate the problems into contributing and non-contributing issues. For example, our PowerPoint issue isn’t something we need to solve, because we know it isn’t contributing to our core problem.
You have to order the problems in order to solve them in the correct order. If you don’t have Internet connectivity at all, then it doesn’t make sense confirming that you can resolve server names. If you solve the Internet issues, what are the things you’re expecting to clear up? What does it mean if they don’t clear up? What are the next steps for that?
Before you begin solving the individual problems, have a theory on what solving that problem should do to the system. What symptoms are you expecting to clear up? What does it mean if specific symptoms don’t go away and how does that alter your troubleshooting plan?
You can use this in everything
I used technology in my examples because it’s what I know. But if you think abstractly you can use these same processes to generate questions about your car repair, your home fixes, your medical care.
“What do we think are causing these symptoms? Can we test for that? If we confirm that’s the cause how do we treat that? How soon do we expect symptoms to subside? If they don’t subside what could that mean?”
When you can stop being a passenger in these sorts of engagements, it can help you feel more confident about the outcomes, more reasoned in your decision making and more at peace with whatever money you’re shelling out.
-
Decision Rights — Communicating How Choices Get Made
Decision Rights — Communicating How Choices Get Made
Advice for leaders
Photo by Beth Macdonald on Unsplash Companies seldom have issues generating ideas and paths forward on problems. In fact, you almost get too many ideas to be able to sift through, evaluate and ultimately implement. But a bigger problem teams have isn’t generating options, but choosing which option to go forward with. (The next issue is aligning resources, but that’s a future topic) The issue of deciding on a course of action is further exacerbated when we have groups of people working on a problem with no clear idea of who the decision owner is.
At Basis Technologies we follow many of the principles and practices of the Conscious Leadership Group. The trainings we’ve had have been invaluable for me as a leader, but one of the best takeaways so far has been the concept of Decision Rights. In a nut-shell, decision rights are a clear definition of who will make a decision for any given situation. I’ve been using decision rights a lot more now that my team has grown and we’re spread out across three countries. The benefits of easy informal communication have begun to disappear as my organization grows and I needed something more formal to ensure the team is on the same page.
There are a total of 7 decision rights with each change in decision rights also increasing the amount of time required to reach the decision and the amount of buy-in received from the group. This will make a bit more sense as I walk through the 7 decision rights really quickly.
Decision Rights
- Leader — We are all pretty familiar with the leader decision right. It’s just like it sounds, the leader of the group (assuming there’s one clearly defined) will make the decision on his/her own.
- Leader with Input — The leader will gather input from others before making their decision. The leader usually will be responsible for soliciting the information they feel is necessary for input to their thought process.
- Subgroup — A small team of people are put together to make a decision. The team is typically made up of Subject Matter Experts (SMEs) that drive all aspects of the decision making process.
- Subgroup with input — A subgroup with input means that the subgroup still decides, but solicits information from outside the group as well, before making a decision.
- Majority Vote — A group discussion of some sort ensues, followed by a voting period. Everyone should have an opportunity to voice their thoughts and concerns prior to voting. Think of it like an election, where each candidate (or view point in our scenario) has an opportunity to discuss their feelings on the situation. After that period has finished, voting occurs and majority wins. The leader of the group or organization will decide what type of majority is needed, whether it be just a simple majority, two thirds majority etc.
- Consensus — Consensus happens when there is nobody that is opposed to the decision being made. It doesn’t mean that they can’t have doubts or reservations, but they’re not actively against it. This is your classic dinner planning scenario. You’re not against steak, even though you’d rather have pasta, but the rest of the group wants steak and you can get behind it. But just like your dinner plans, consensus decisions can be difficult to reach, so it’s wise to have a fall back decision right in the event you can’t reach consensus. Any of the previously mentioned decision rights can work, but I typically fall back to Leader with Input.
- Alignment — Alignment is when every one is in full support of the decision being made. There is no dissent. This is the hardest of all the decision rights to meet. If you can’t get alignment on dinner, getting alignment on transformational change can be very hard. Like the consensus decision right, it’s important to have a fall back decision right in case alignment cannot be reached.
With these 7 decision rights laid out, we can talk about buy-in vs time. Depending on the urgency of the decision that has to be made, some decision rights might seem more obvious than others.
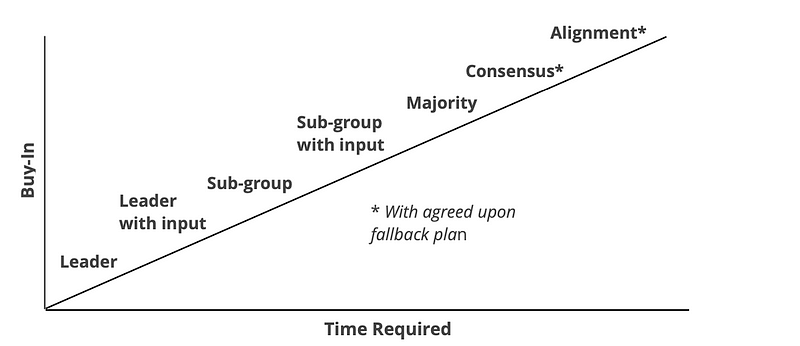
Decision Rights Graph — from the Conscious Leadership Group In the above image you can see the various decision rights plotted on a graph, with the axis being buy-in and time. These are typically the two constraints that we’re working with when it comes to decision making. Buy-in can be incredibly important for large transformational change, but time may be of the essence when we’re trying to make a decision about something this quarter. There is no right or wrong answer for choosing a decision right. It all boils down to the situation at-hand and the constraints that you’re working under. If you’ve got more time, achieving more buy-in makes sense which can lead you to decision rights like Alignment or Consensus. Any decision typically benefits from a larger buy-in from the team. The problem is not every decision has the time necessary to get there, which makes some of the other decision rights attractive and appropriate for the situation at hand.
Communicating Decision Rights
I don’t use formal communication for every decision right in our team. I typically reserve it for broad impacting decisions that I know many people will have feelings about. I also don’t discuss decision rights when it’s Leader decides, because then it’s usually quite clear. It’s a terrible feeling thinking you’ve got input on a decision when you don’t. If I come to the team with a decision already made, I make that clear with the delivery of the decision. Again, this is a rare occurrence, but it does happen.
When I am communicating decision rights, it’s usually in this old, antiquated form of communication called a “Meeting Agenda”. Some of you may remember those from back in the day when it was important to know what you were going to be spending 1.5 hours of your life on. In the meeting agenda I try to lay out a few things.
- What the decision to be made is
- The timeframe allotted to make the decision (often just the length of the meeting)
- What the decision right is
- What the fallback decision right is (if applicable)
- Any tools being used to generate decision options (Brainstorming, Pros vs Cons, 6 Hats, etc)
With these points in hand, everyone clearly understands their part in the decision-making process and how decisions gets made. Even if people don’t agree with the final decision, the process to which it came into being is well-understood and transparent. The agenda doesn’t even have to be super-exhaustive. Here’s an example agenda I’ve used in the past.
Lets get together and discuss namespaces moving forward.
Problem: We need to decide if we’re going to have a single namespace per environment or if namespaces will be broken down by application. Single namespaces are advantageous in test environments, but can become unruly in production. Multiple name spaces can complicate environment management and will force specific patterns of referencing apps in pods, since you’ll have to use the FQDN. None of these are hard, but we need a specific choice.
Meeting Outcome: Decide on single name space or multiple name spaces. Decision Model: Group Consensus with a fall back of Leader Decides with input from staff, if we can’t come to a consensus.
Pros/Cons Idea Boardz
It’s just enough information to get everyone on the same page without taking tons of times crafting time blocks that probably won’t be honored anyways. (Although if you’ve got the time for a more detailed agenda it’s totally worth it. I’m just saying that there’s still value in a brief agenda if the alternative is no agenda at all)
Wrap-up
Decision rights can be a tricky thing once you’ve moved beyond the leader decides tier. Making sure people involved and impacted by the decision are aware of how decisions are made can lead to greater buy-in even after the decision has been made. Communicating these decision rights can be a huge boost to involvement and productivity. It also forces you to make rationale decisions about the two constraints of every decision, time and buy-in. The more time you have the more you can invest in getting larger buy-in. But if time is short, you may have to make due with less buy-in so that you can get the ball rolling on whatever decision you make. These pressures exist whether you acknowledge them or not so its better to go into the situation eyes-wide-open. It can even help you communicate why such a narrow buy-in was chosen. Not every decision has a time-horizon that can afford alignment or even consensus. Does this mean some decisions are sub-optimal? Of course. But a sub-optimal decision is way better than no decision at-all.
If you’d like to further dive-in or see a visual representation of Decision Rights, I’ve linked a video below and I encourage you to checkout the Conscious Leadership group.
-
Terraform, AWS, and Idempotency
Terraform, AWS, and Idempotency
A bug in Terraform? Or a misunderstanding of how a particular stanza works? Or maybe even our own automation around Terraform?
Photo by James Harrison on Unsplash Hopefully, this is only part 1 of this series as it doesn’t really have a satisfying ending so far, but still a story worth sharing. We encountered an error in Terraform that was transient but seemed to go away on its own, most likely some race condition. This post is going to walk through that failure. It’s a bit more technical than some of my other posts so those who come for the leadership thoughts might have their eyes glaze over. Your mileage may vary.
A bit about our deployment process first. We use a blue/green deployment strategy in our environment (minus the database). Automation around Terraform is responsible for bringing up the second application stack and deploying code to it. During the creation of that second stack, we received an error message we had never encountered before.
Error: error creating EC2 Launch Template: IdempotentParameterMismatch: Client token already used before.
status code: 400, request id: 4c6edce7-7497-4884-ab63-f215f9b82f6e
on ../terraform-asg/main.tf line 33, in resource "aws_launch_template" "launch_template":
33: resource "aws_launch_template" "launch_template" {There were a few things that needed to be researched here.
The IdempotentParameterMismatch Error
When an action is idempotent, it means it can be performed multiple times without changing the result beyond the initial application. I
n practice what this usually means is if I run command X, the command is aware if it had been run before in this context and may skip the usual application of the command and instead return a status or a result. A simple example is the
mkdircommand when you use the -p flag (which tellsmkdirto create the full path if it doesn’t exist).If I run that on my local workstation the following happens.
mkdir -p /tmp/test
ls -l /tmp/|grep test
drwxr-xr-x 2 jeff.smith wheel 64 Jun 9 06:31 test
mkdir -p /tmp/testThe
mkdircommand created the path/tmp/testand we can see it was created successfully. When I run the command again, it completes successfully with no error message.That makes this command idempotent. No matter how many times I run this command, I know in the end I’ll get a successful result and that the path
/tmp/testwill exist. Now contrast that with justmkdir.mkdir /tmp/test2
ls -l /tmp/|grep test2
drwxr-xr-x 2 jeff.smith wheel 64 Jun 9 06:35 test2
mkdir /tmp/test2
mkdir: /tmp/test2: File existsNow with mkdir, on the second execution I get an error message, which is a different end result than my first execution. The directory exists, but the error code I get back is different. That makes this a non-idempotent operation. But why do we care? Well in the second example I need to do a lot more error handling for starters. And this is a basic example.
When doing something like creating infrastructure, it could result in launching more instances than you intended, which is what this
IdempotentParameterMismatcherror is designed to prevent.When you make an AWS API call to create infrastructure, just about every endpoint (to my knowledge) does this is in an asynchronous fashion. What this means is your API call returns immediately but the work of actually creating the infrastructure you requested is still in progress. Because of this you typically need some sort of polling mechanism to determine when the operation has been completed.
Several AWS API endpoints support idempotency, which allows you to specify a client token to uniquely identify this request. If you make the same API infrastructure creation call and use the same client token, instead of creating a new instance, it will return the status of the previously requested instance. When creating infrastructure programmatically this can be a big safety net to avoid creating many copies of the same infrastructure. And that’s where our error comes in.
The error is stating that we have already used the client token. Digging into the documentation a bit, a more specific meaning is that we changed parameters in the request but reused the client token, meaning the API doesn’t know what our intent actually is. Do we want new infrastructure with these parameters? Or are we expecting already existing infrastructure that matches those parameters? To be safe, it throws this error.
The user is always responsible for generating the client token. But in this case, the user is actually Terraform. That created some surprise and relief on our part since it meant it most likely wasn’t any of our wrapper automation. But we still needed to be sure. The first thing we did was an attempt to find what client token was used and was it actually used twice.
Luckily the error gave us a
RequestIdwhich we used CloudTrail to look up. In therequestParametersfield of that request we were able to find the ClientToken used."requestParameters": {
"CreateLaunchTemplateRequest": {
"LaunchTemplateName": "sidekiq-worker-green_staging02-launch_template20220510183630312700000005",
"LaunchTemplateData": {
"UserData": "",
"SecurityGroupId": [
{
"tag": 1,
"content": "sg-0743bcbd08cadba1d"
},
{
"tag": 2,
"content": "sg-6daf421e"
},
{
"tag": 3,
"content": "sg-0818108e24803a418"
}
],
"ImageId": "",
"BlockDeviceMapping": {
"Ebs": {
"VolumeSize": 100
},
"tag": 1,
"DeviceName": "/dev/sda1"
},
"IamInstanceProfile": {
"Name": "asg-staging02-20220510183628901400000003"
},
"InstanceType": "m4.2xlarge"
},
"ClientToken": "terraform-20220510183630312700000006"
}It looks sufficiently random in the same format that Terraform often uses to generate random values.
It definitely didn’t appear to be something we generated. We then decided to search all requests in that time frame to see if any of them had the same client token.
Sure enough, there was a second request made that reused the same Terraform module (which we wrote) to generate a second ASG and launch template.
"requestParameters": {
"CreateLaunchTemplateRequest": {
"LaunchTemplateName": "biexport-worker-green_staging02-launch_template20220510183630312700000005",
"LaunchTemplateData": {
"UserData": "",
"SecurityGroupId": [
{
"tag": 1,
"content": "sg-0743bcbd08cadba1d"
},
{
"tag": 2,
"content": "sg-6daf421e"
},
{
"tag": 3,
"content": "sg-0818108e24803a418"
}
],
"ImageId": "",
"BlockDeviceMapping": {
"Ebs": {
"VolumeSize": 200
},
"tag": 1,
"DeviceName": "/dev/sda1"
},
"IamInstanceProfile": {
"Name": "asg-staging02-20220510183629183700000003"
},
"InstanceType": "m5.xlarge"
},
"ClientToken": "terraform-20220510183630312700000006"
}As you can see, there are differences in the request, but the client token remains the same. Now we’re starting to freak out and think maybe it is our code, but we still couldn’t see how.
Generating the ClientToken
As I mentioned previously, generating the client token is the job of the user from AWS’ perspective. From our perspective, that user is Terraform. We’re not GO experts by any stretch of the imagination on our team (although we’re looking for a few good projects to take it for a spin. We have a lot of interest).
But in order to understand how the client token gets generated, we were going to have to look at the Terraform source code. After a little digging, we came across the code living in the terraform-plugin-sdkas a helper function.
func PrefixedUniqueId(prefix string) string {
// Be precise to 4 digits of fractional seconds, but remove the dot before the
// fractional seconds.
timestamp := strings.Replace(
time.Now().UTC().Format("20060102150405.0000"), ".", "", 1)idMutex.Lock()
defer idMutex.Unlock()
idCounter++
return fmt.Sprintf("%s%s%08x", prefix, timestamp, idCounter)
}In this function, the author is generating a timestamp accurate to the second. It’s possible that multiple executions could hit in the same second-time span, but the value also gets a counter appended to it.
The counter is in a mutex so the value of
idCounteris shared across executions and the mutex prevents concurrent execution. There should be no way that this function generates the same client token twice. But that doesn’t mean that the function calling for the client token isn’t storing it and possibly reusing it.Wrap Up
This is where our story ends for the moment. We started to look into how and where the client token was getting used, but since we felt strongly that this was going to be related to a Terraform issue of some sort, we had to shift gears for a solution. We weren’t going to run a custom patched version of Terraform. We weren’t going to upgrade on the spot. And we weren’t going to wait until a PR got approved, merged, and released, so that put us on a different remediation path.
Our current fix was to specify a
depends_onargument for the two resources in conflict. Other times when the error happened, we noticed it was always these two resources in conflict, so the hope was that thedepends_onflag would prevent these from being created in parallel.So far that hope has paid off and we haven’t seen the error in any environment again. But we plan to continue to research the issue out of nothing more than morbid curiosity. It might lead us to a bug in Terraform, a misunderstanding of how a particular stanza works, or maybe even our own automation around Terraform.
Who knows? If we find it, you’ll be sure to find a Part 2 to this article!
-
I think the meeting and the medium for the meeting can be separated.
I think the meeting and the medium for the meeting can be separated. Yes, meetings are generally unproductive because people don’t respect the true cost of a meeting. If the hourly rate of a meeting was deducted from the organizer’s pay, they would probably treat it with more respect. But I don’t think meetings are inherently bad. What would be the tool for gathering input, feedback and decision making look like? Back and forth on a confluence document? After 4 exchanges it usually ends up in a meeting. Which is not uncommon for me to use as a benchmark. Try to solve things via email or some other medium, but after X many exchanges, it moves to a meeting with a clear agenda, decision to be made, decision rights (who makes the decision?) and method of getting to that decision. (Brainstorm, Pros/Cons exercise, 6 hats etc)
-
Inbox Zero
Inbox Zero
Photo by Krsto Jevtic on Unsplash Inbox Zero is another one of those productivity hacks that you hear a lot about in tech circles. For those of us with an unread message count in the thousands, it sounds like a far-off intangible dream like faster than light travel or sensible gun laws.
But after doing inbox zero for a few years, I’m here to tell you that the dream can be had! Inbox Zero is achievable if you remain focused and disciplined.
What is Inbox Zero?
Inbox Zero is an email management strategy dedicated to keeping your mailbox from reaching the levels of insanity where you simply give up on any hope of actually managing it. In your despair, the unread message badge sits on your mailbox as a scarlet letter, informing those around you that you’re as disorganized as you feel. The goal of inbox zero is to get your mailbox to empty at the end of every day.
That sounds like a heavy lift, but the secret to inbox zero is that you don’t actually have to respond to every email in the same day. It’s about processing your mail down to zero every day.
The thing about an overflowing inbox is that you never know what might be lurking inside those 1352 messages that you have as unread. It might be an important ask from a senior leader. It might be a change to your kid’s violin schedule. It could be a reminder that your car registration is set to expire. The uncertainty of what’s buried in those messages causes many of us a lot of subconscious stress. A feeling of being out of control begins to invade our psyche and we can never fully relax.
The goal of inbox zero is to reduce that stress not by responding to all of your email at once but by getting an understanding of what’s in your mailbox so that you can make a conscious decision about what to do with it.
The nature of email
When you think about emails that you receive, they really boil down into one of four categories.
- Something you need to do
- Something you need to know
- Something you need to have
- Garbage
The “something you need to do” category is probably the one we’re all the most familiar with. Knowledge workers get many of their tasks via email, whether it be an assignment from your direct manager or just the need to respond to the email because a question has been raised that you have the expertise to handle.
Something you need to know are those informational emails that sometimes turn into things you have to do. It might be a heads up that a particular meeting is occurring, a policy is changing, your kid has a change in soccer practice, etc. You don’t always have to do something in response to this knowledge sharing but there’s often a time constraint to it, which makes processing it in a timely fashion pretty important.
Something you need to have is really a riff on something you need to know. It’s the transmission of some data you need to have access to in the future. Think of spreadsheets, concert tickets, receipts etc. It’s important that you consider the likelihood of needing to recall this data later. The emailed receipt from your coffee visit probably doesn’t have much value, but the receipt from a shipping order could be useful up until you receive the item. It’s important to be critical about how you evaluate these types of emails or else everything can fall into the category of “something you need to have” and you become the digital equivalent of a hoarder.
The last category, garbage is pretty self-explanatory. Junk mail, chain letters from Aunt Isabelle, the 500 donation requests from your local political party etc. If it doesn’t fall into one of the categories I listed earlier, then chances are it’s junk.
Processing Email
As I mentioned before the trick to inbox zero is processing all of your email. By processing your mail and getting an understanding of what’s in your inbox, you can achieve some level of peace, because at the very least you know there’s not a time bomb waiting for you deep in your unread count.
When you process your email, identify what type of email it is. If it’s something you need to do, ask yourself if you can accomplish the ask in a short amount of time. My personal limit is 5 minutes or less. Many people use 2 minutes or less as their limit. Whatever limit works for you, set it and take care of all messages that meet that criteria, whether it be performing a task or just responding to the email. If you can’t finish the task within your time limit, move the email to a “To-do” system or folder. I personally love the Getting Things Done methodology and have been using it myself for over a decade now. But no matter what your system is, the key is to move it out of your “Inbox” and somewhere dedicated to work that needs to be done. It might just be a separate folder in your mailbox or a more sophisticated solution like OmniFocus or Todoist. The key is to make sure it’s out of your inbox!
For things that are “something you need to know” or “something you need to have”, the same rule applies. Get it out of your inbox into something that’s more specifically for those types of things. I personally use DevonThink as a document storage manager. Anything I need to keep or store I put in DevonThink with a set of tags that’ll help me to retrieve it later. But you don’t need anything as robust as DevonThink. You can come up with a standard folder system in your mailbox or on your computer’s filesystem. If you intend to store files or mail on your filesystem, I recommend using a cloud storage option like Dropbox or iCloud Drive to make sure that you have access to your files on all of your devices. (If you’re interested in how I file documents, drop me a note and I’ll write a blog post on it) But again, the theme is to get it out of your inbox! Just the act of handling the message will give you the context necessary to decide if you need to deal with it immediately or not. You might process a note and realize that “I need to deal with this right now and then I can just delete the mail.” Or you might end up converting that “need to know” into “something to do” and transferring it to your to-do list. But if it sits in your inbox, flagged as unread, it will gnaw at your psyche and slowly drive you insane.
When it comes to garbage mail, I say that you need to be as ruthless as possible. Flag messages as junk so your mail client can learn what’s valuable and what’s not. Unsubscribe from newsletters that you don’t read with a passion. Opt-out of marketing emails that you inevitably get subscribed to when you make a purchase. Lastly, create email rules for those particularly stubborn mail senders that will route those mails directly to the trash bin when all else fails. You’d be amazed how much noise you can cut out when you’re diligent about keeping junk mail from hitting your inbox. You’ll never get all of it, but even a 30% reduction will have a noticeable impact.
When to process email
Another trap that many of us fall into is keeping our email client open all day. Don’t do it! I try to limit email processing to 3 times per day. In the morning when I start the day, in the afternoon after lunch and one final time for the end of the day. All other times, I try to keep my mail client closed. There’s one caveat to this approach though. If you use Outlook as your mail client, you might run into an issue where your calendar application and your mail application is one and the same. Closing out your email could also mean locking yourself out of calendar reminders, which is a deal breaker. It’s for this reason that I personally migrated to using the standard Apple Mail app and Busy Cal for email and calendar management. By having two separate clients, it’s easy for me to divorce these two tasks. If you’re stuck in Outlook, you might want to consider changing your fetch frequency to something longer. I avoided this approach, so your mileage may vary.
Keeping your mailbox open is a distraction as the notification bell continuously pulls your focus away from what you’re doing and sucks you into the drama of the mailbox.
Wrap-up
Inbox Zero may sound like a fantasy but I assure you it’s possible. When you decide to give inbox zero a shot, I recommend that you plan to spend an entire evening focused on processing your inbox. (Depending on how many emails you have to go through of course) Getting out of mailbox debt will be more time consuming than you might imagine, but it’s energy and effort well spent. If you have an overwhelming amount of email and you can’t fathom processing it all, there’s always the option of email bankruptcy where you concede to your mailbox, declare to folks that you won’t be responding to anything sent prior to this moment and you do a massive delete on all the mail in your mailbox. It’s a gutsy move but sometimes it’s necessary. But whether you get there through processing your inbox or declaring email bankruptcy, achieving inbox zero will give you the joy necessary to keep up with it.
Good luck!
-
The Office is Dead….Long Live the Office
The Office is Dead….Long Live the Office
Photo by Nastuh Abootalebi on Unsplash NOTE: The views expressed here are my personal views and don’t reflect the views or position of my employer.
The office is dead. It’s not dying or on life support, it’s just dead. The pandemic put it on life support and employers finished the job when they opened the doors to fully remote hiring. When teams became spread across the country, the purpose of the office died and it accelerated a shift that was bound to happen anyways. Remote work became the primary means of working and collaborating.
The value of the office
The real value behind the office was conformity, collaboration and indoctrination. Conformity had a range of ways in which it was exercised. Everyone had the same mouse, the same keyboard, the same monitors and this allowed companies to streamline the support process. In many offices, dress codes enforced a standard that would breed a set of attitudes. The more formal the dress code, the more professional the setting. Unless of course you were in Hollywood, Wall Street, Sales etc. But that was the theory anyway. How people worked, when they worked were all managed under the watchful eye of leadership, where too many coffee breaks were easily noticed. The loss of that conformity has sent many managers into a bit of a panic.
Collaboration was a huge hit in the office. No one will ever convince me that a video conference meeting is as effective as in-person meetings. When your best friend goes through a terrible breakup, you’d never say “Grab a beer and meet me on Zoom and lets talk about it.” No, you go to the bar and you have face to face communications about it. And if you can’t go to the bar, you have a Zoom call and complain about how much you wish you could be in-person doing the same thing you’re doing on a “just as effective” medium. If it’s not as effective for drowning your sorrows, it’s definitely not as effective for collaborating on complex topics, thoughts and ideas. Being able to share the same pen, on the same whiteboard without losing 3 seconds of audio every time you talk at the same time is priceless and something that I don’t think remote work will ever replace. That’s not to say that remote work is incapable of producing good collaboration, because it most certainly can. It just takes more dedication, planning and participation by all attendees.
Indoctrination is another hard one. Replicating a culture remotely is a challenge that I think many companies are struggling with. It’s hard enough to build a culture in person. We lose the rituals of culture building as they get lost in translation to video conferencing. The activities that resonated in-person don’t resonate through the lens and we’re still trying to figure out how to replace them. I think we’ve all learned that a lift-and-shift of cultural activities doesn’t work. Sharing a team lunch on camera isn’t the same and quite hoenstly turns into a disgusting affair really quickly.
With these three things listed, there’s one thing that’s a bit of a glaring omission and that’s work. The office has never been a place where “work” is super efficient. You’re constantly bombarded with distractions, drive-by visits, unexpected delays in your commute just to name a few. For many people, the office was the only option for work, so its effectiveness was never deeply considered. Prior to the pandemic, most people hadn’t transformed a space in their home to be effective work from home (WFH) employees. Those employees that were already fully remote learned this secret a long time ago and have been reaping the productivity gains ever since. But people new to the WFH game had to figure it out on their own. Many of us still don’t have a great work from home setup due to space constraints. Those people are probably longing for the reopening of the office, but they’ll find that what they come back to is just a shell of its former self.
The flood gates of remote hiring
Companies have been desperate to hire the last year or two. Many clever companies decided to open the flood gates and start hiring remotely. Even yours truly was a staunch supporter of the in-office lifestyle. I preferred people in the office, collaborating and working together, drinking the indoctrination kool-aid. But I also sensed the winds changing. Now 4 out of my last 5 hires have all been remote. My team is almost 50% remote now and honestly, one of my employees has such a long commute he might as well be considered remote.
The point being, I will never return to a world where everyone is in the office. It’s just not possible. Even if we forced the local people back into the office and allowed the remote people to stay remote, it creates an even worse scenario. Your team becomes bifurcated as they self-organize into remote and in-person silos. Yes, we should be doing everything in slack and yes, we should make sure every meeting has a Teams invite. But if you can have a meeting with three people in the office and one remote person, human nature dictates the path of least resistance and that four person meeting gets cut down to a three person meeting real fast. Guess who gets dropped.
Same with the remote people. You’re trying to collaborate with people remotely and even though you have a great microphone, solid lighting and an HD camera, you’re working with a bunch of people trying to figure out the antiquated video conference software in the room. The microphone sucks so you can’t hear Joey, who always sounds like he’s talking at a funeral. Mary gets up and starts doodling on the whiteboard, forgetting that you can’t see the whiteboard. Now we spend 10 minutes adjusting the camera to point at the white board, only for it to pan back to the first person who starts talking. Yeah, you’re familiar with this nightmare. There’s no need to rush back to it.
If everyone is remote, everyone is on the same playing field. And while it may not be as effective as everyone being in the office, it’s way more effective than having some people in the office and some people remote. If you’ve started down the path of remote hiring, the current incarnation of your office is dead.
The Future of the Office
The office was never about work. But now we can’t even afford to pretend that it’s about work. Most of us have created a work from home setup that rivals anything the office would provide. It’s tailored to our needs and our tastes. When we go to the office now, it’s a step down in every category. Even my wife has a 34" widescreen monitor now. People are spending major dollars on their chairs, their keyboards, their mouse because now it’s an investment. The occasional Friday at home didn’t warrant the investment we’re willing to make now that it’s 5 days a week. And that means companies are either going to have to adjust their budgets and their equipment flexiblity or they’ll need to find another way to entice people back to the office. It’s hard to compete with great ergonomics, beautiful displays and a 2 minute commute.
The office still rules in the areas of indoctrination and collaboration. Collaboration has to be intentional though. For starters, every meeting space has to treat remote workers as first class citizens. That means solid audio and easy to use camera setups that are well maintained. The tech in these rooms has to be designed with these hybrid meetings in mind. I don’t think it will ever be as good as being in-person or everyone being remote, so these items are tablestakes just to get people considering a trip downtown.
Where the office will truly shine though is in collaboraton between people who normally don’t collaborate. Building relationships and strengthening netowrks is the place where the office still has clear dominance. For example, I went into the office a month or so ago for a meeting run by our facilities team. I don’t work with the facilities team often and certainly not since going full remote 2 years ago. But it occurred to me that I talked with Jan (our facilities manager) every day prior to the pandemic. Why? Because we would always cross paths in the kitchen and strike up a conversation. The kitchen was a sort of central access room and because of the respective locations of our desks, we would constantly find ourselves running into each other in the morning and afternoon. A happy little accident.
The office was great for building these sorts of connections. But now we’ll want to be more deliberate. How do we construct the office space to generate these common access patterns. Do we need to rethink the idea of these silo’d teams, isolated to one specific spot in the office? How do we design the layouts to encourage and entice foot traffic from many different groups, creating the conditions for the happy little accidents Jan and I shared for over 4 years? The office needs to look very different than how we left it, with these thoughts front and center.
The need for networking becomes apparent when you have more than 4 people from the same department in the office at the same time. The desire for human contact is palpatable. When I go to the office, I spend more time talking and catching up than I do working. Sure that will die down with the frequency of office visits increasing, but the long tail on that is probably bigger than you think.
Many companies aren’t considering a five day a week return to the office schedule. Some are doing the three days in the office, two days remote or a version of that. But many companies don’t dictate who works on what days, so you might not get the colalboration (and therefore the productivity) that you were expecting because people aren’t in the office on the same days. That also means you’ve got a much larger number of personnel combinations, meaning you might not see the same sets of people all the time.
Networking and specific collaboration events is where the office will prove its value. But with a shift away from “where work happens” the office design and layout also needs to change. New tools need to be brought to the office to streamline the in-person/remote collaboration efforts. If you’ve still got people pointing their laptop web cams at the whiteboard for the remote folks, you won’t succeed in this new era of office work. We’ll need to rethink how people are grouped together for work as well. How do we entice the chance meetings that were fueled by common spaces such as the lunch and coffee areas? Does grouping people by departments still make sense if the office isn’t about general work getting done?
These are all questions that we’ll need to ask ourselves as we figure out where the office fits into corporate life. I believe the office does still have a future but only if we rethink its purpose and the organization’s commitment to that purpose. You’re not going to lure people back to the office with snacks and unlimited soda. The office will have to offer something that can’t be found at home. People and their need for interaction both personal and professional will be the cornerstone of the weekly office visits.
-
Treating OPS Teams Like Product Teams
Platform as a Product
Photo by Arno Senoner on Unsplash Operations is one of those areas that many people in the company struggle to fully understand. The depth and breadth of responsibility varies per organization, with production support being the only thread you find consistently in companies. (And even that is changing with you build it, you run it becoming popular)
But infrastructure operations is too important of a component to be relegated to the annals of cost-center accounting. Smart organizations understand this and invest heavily in Operations teams. My job as a leader is not only to evangelize what it is we do, but to tell a story that’s relatable to stakeholders so that they understand how our role impacts their day-to-day lives. Most people don’t spend a lot of time thinking about disaster recovery, high availability or even ongoing maintenance of the things we build. Everything that is built and operating has some sort of maintenance cost associated with it. For many, it’s easy to think once a product is launched, it just exists on its own with no real need future management. But software is never finished, just abandoned.
With this lack of clarity on the value my team brings, I’ve been working through different ways to more effectively evangelize what it is we do. This led me to the idea of managing the Operations team like a product team, using similar techniques, roles and producing similar artifacts as part of how we manage what we do.
Over the next few months I’ll be working to make this shift within my team and chronicling some of the experiences we have, the challenges and the thoughts around this transformation. I’m still working on a way to tie these things together into some sort of easily searchable series, but know that this won’t be the end of the conversation. I’ll have some sort of tag to use across the entire series.
What’s the Product?
The first thing I had to ask myself when I cooked up this idea is, Exactly what is the product that I’m “selling”? That question was actually easier to answer than I thought. At Basis we’ve been pretty adamant about building as much of a self-service environment as possible for engineers. Unfortunately the self-service approach never took on a polished, holistic view the way a product would. We would solve problems using a familiar set of patterns, but we’d never actually think about them from the perspective of a product. What you end up with is a bunch of utilities that look kind-of the same but not enough for you to make strong assumptions about their behavior, the way you might with say Linux command line utilities.
With Linux command line tools, whether you realize it or not, you make a bunch of assumptions about how the command functions. Even if you’ve never used the command before in your life, you know that it probably takes a bunch of flags to modify the behavior of the script. The flags are most likely in the format of “- or –”. You know that the output of the command is most likely going to be text. You know that you can pipe the output of that command to another command that you might be more familiar with, like grep. Leveraging these behaviors almost becomes second nature because you can count on them. But that didn’t just happen naturally. It took a deliberate set of rules, guidelines expectations etc. This is what’s missing from my team’s current approach to self-service.
So back to the original question of “What’s the product?” I’ve been working on a definition that helps to frame all of the subsequent questions that follow, like product strategy, vision etc.
What is the product?
A suite of tools and services designed to support in the creation, delivery and operation of application code through all phases of the software development lifecycle.
It’s a bit of a mouthful at the moment and I’m still tooling around with it a bit but I think it’s important to conceptualize what the product is that Operations is selling. The best analogy I’ve been able to come up with is the world of manufacturing.
As an inventor or product creator, you might design your product in a lab, under ideal conditions. But you have no idea how to mass produce it. You have no idea how to source the materials effectively for it. You have no idea the nuanced problems that your design might create when you’re attempting to create 200,000 of whatever you created.
If you’re a solo creator, you’d probably start talking to a manufacturer so that you can leverage their expertise as well as their production facilities to help turn your dream into a reality. If you work for a large enough company, you might have your own internal manufacturing team that specializes in various types of product creation. This is the analogy for operations. We take application code that the developers have created, then using our infrastructure and processes, get it to a state that’s production ready.
I’m sure given a little scrutiny this analogy will show some holes, but I think it does a good job of at least getting people in the mindset for viewing infrastructure and the supporting services as a product. The final product of a manufacturing line is a blend of design and production, similar to the way the quality of the application is a blend of design and production.
How does this change the way we look at ProdOps?
I can imagine many people are reading this and thinking “What’s the big deal, so it’s a product. How does that change anything?” Depending on your team, it might not change anything. But for many groups, once you start looking at operations as a product team, it really starts to change your perspective on the management of your infrastructure. But most importantly, if we get our minds right, thinking about Operations as a product opens us to a world of best practices, workflow management techniques, reports and communication patterns just to name a few. A perfect example is the idea of user personas.
In the operations world, we have a vague idea of who are “customers” are internally. Not only that but we have a very specific idea of what a developer should know and care about. Our expectations manifest themselves on how we interact with developers. Our forms, our workflows our RTFM approach, all are based on our elevated expectations of developers. But if we approach this from a product centric viewpoint, we’re forced into a customer centric viewpoint as well. Nobody would tell their customers “you should just be more sophisticated” or “you should just know that”. It wouldn’t be great for sales. This is one of the reasons why product teams develop user personas as a way to represent their target customer. They might even create multiple user personas to represent the breadth of their potential customer base, as well as how those personas might use the same tool differently than other customers. User Personas are in no way revolutionary, but thinking in terms of a product makes their adoption in an operations setting a much more natural transition.
Wrap up
As I mentioned previously, this is really a big experiment on my part. At the time of this writing, I’m very early in the process. But I hope to use this blog to share parts of the journey with you. Hopefully you’ll be able to learn from some of my missteps.
In the next part of this series, I’ll be writing about the establishment of the product vision, product strategy and product principles and how they play their parts in building the roadmap for the Operations infrastructure.
-
Organizing Tickets for OPS Teams Part 2
Organizing Tickets for OPS Teams Part 2
Photo by Alvaro Reyes on Unsplash In my previous article I laid out some of the ground work for how I setup my team’s workflow management. In this article I’ll go a little deeper, specifically around ticket types and my labelling process in order to get more data from our ticket work so that I can effectively manage the team.
Ticket Types
As previously mentioned, my team uses JIRA for ticket management. Any ticket system worth a damn will have some concept of ticket types so the lessons presented should still be applicable. I’ll be writing directly about my JIRA experience, so your mileage may vary.
The first thing when considering what ticket types to create is how I want to report on this data in the future. If I don’t care about the difference between a Defect and a User Story, there may not be much value in separating the two ticket types. With reporting in mind, I go about laying out the different ticket types I want as my first layer of reporting.
- ProdOps Tasks — This ticket type is designed for end users (developers, QA staff, etc) who need support from my team for something that is need in “quick” fashion. Quick might be minutes, it might be days but the important thing is that it can’t wait for the normal iteration planning process of my team to happen. This is interrupt driven work. As a result, the workflow for ProdOps tasks has these tickets skip over the backlog and land directly into the Input Queue.
- Stories — These are larger requests that are going to take time, planning and effort. They might come from customers (again, developers, QA staff, product owners etc) but they’re often generated from within our team. Stories are always capable of being scheduled and therefore go directly to the Backlog upon creation.
- Defects — When a piece of infrastructure or automation that my team supports isn’t working as intended but is not blocking a user’s ability to do their job, we mark this as a defect. An example might be that our automation does an unnecessary restart of the Sidekiq Service, which results in a longer environment creation process. It is a pain for sure, but the user will live. It’s still something we should address, hence the defect ticket. Defects go directly to the backlog.
- Incidents — When a problem is occurring, there’s no workaround and there’s a direct impact to a group of people’s ability to work, that’s considered an incident. An incident exists regardless of the environment it happens in. (No matter the environment, it’s always production for somebody) Incidents skip the backlog and go straight to the input queue. Incidents are often generated automatically via PagerDuty since all of our alerting happens through the Datadog/PagerDuty integration.
- Outage — When we have large system wide outages we create an outage ticket to track the specifics of the larger impact. Because incidents are generated by alerting, when there’s an outage we will often have multiple incident tickets that are all related to the same problem. The outage ticket allows us to relate all of those tickets to a master ticket, as well as use the outage ticket to track the specific timings and events of the larger incident. Outage tickets are generated manually at the declaration of an outage.
- Epics — I use epics to tie multiple stories into larger efforts. I also use epics as a way to communicate what the team is working on in a higher level fashion to my management. My boss doesn’t care that we’re working on moving away from the deprecated “run” module in Salt Stack. (That’s too low level) Leadership wants larger chunks of work to understand what’s happening on the team. Having an epic with a business level objective at its definition is much easier for leaders to follow and understand.
Each of these ticket types were created with two primary things in mind. * How do I want to report on tickets? * How do I want these tickets to behave as it relates to the backlog and input queue?
How do I want to report on tickets?
I create the ticket types based on how I want to report. ProdOps Task tickets were created to get an understanding of not only the demands that other teams are placing on my team but the urgency of those demands. This might be something material like “Need help with a new Jenkins Pipeline” to something routine like “New hire needs access to Kubernetes.” Having these types of requests separated into their own ticket type allows me to very easily create reports around them. (Even with JIRA’s horrible reporting abilities)
Stories and defects when compared to incidents and prodops tasks allow me to get a sense for how much planned work the team is doing versus work that bullies its way into the queue and demands our immediate attention.
Something to consider about ticket reporting. Reporting can be an inexact science. Much of it is subjective when you start looking at the details of a ticket. The thing to keep in mind with this sort of reporting is that we’re looking at the data for themes not for precision. Do I care that I had 3 tickets get categorized incorrectly as defects? Not when 60% of my tickets are defects. The 60% number (if true) helps to draw my focus. When it comes to reporting, look for a signal, but then validate that signal. Don’t just assume the data is accurate and start making changes. It’s just too difficult to keep the data completely accurate, so you should always look at your ticketing reports through that lens.
How do I want these tickets to behave as it relates to the backlog and input queue?
Tickets that are too urgent to go through the planning and prioritization process need to be made available to the team for work immediately. By creating those as separate ticket types, it’s easy for me to create a different workflow that allows these tickets to jump straight into the Input queue. I can also add functionality to flag these items or take other actions to raise their visibility to the team. But the ticket type drives my ability to handle them differently.
Different ticket types for end users to leverage also makes it much easier for them to interact with us as a team. Almost exclusively we tell our users to create their tickets as ProdOps Tasks. The majority of the time, they’re items that need to be addressed sooner rather than later. In the cases where their tickets actually can be scheduled we just convert the ticket to the appropriate ticket type (based on our reporting needs) and we move it to the backlog for the next planning meeting. This removes the anxiety of choosing the wrong ticket type from the user. Create it as a ProdOps Task and we’ll do the rest.
Ticket types can go a long way in helping you to create meaningful reports on the activity of your teams. It also gives you a way to slice your workload to see how different areas are impacted. The average time to close a ticket might be 14 days but then you find out that if you separate that by ticket type, the incident tickets are the outlier for resolution time. Maybe your team isn’t consistent about closing those particular ticket types for some reason. Or perhaps the automation that you use to resolve the tickets through monitoring isn’t setting the “Resolution” field on the ticket appropriately.
Sometimes though you want a level of reporting that goes beyond what ticket types allow for. This is where I use labels.
Using Labels for Reporting
Labels are pieces of metadata that you can add to tickets to give them a bit more description. The beautiful thing about labels (and metadata generally) is that they’re so flexible. The horrible thing about labels is that they’re so flexible.
The reporting on labels in JIRA isn’t the greatest, but the pain of pulling this data into a separate tool and figuring out the JIRA data model is much higher than just dealing with the reporting shortcomings, so here we are. When it comes to labels, relying on team members to always label tickets has varying levels of success. Some team members will be extremely diligent about it while others will be more lax. It’s good to have a process where you can validate that labels have been applied to tickets appropriately.
The issue I find with labels is that it can be difficult to know whether the label is just missing on a ticket or if that ticket doesn’t meet the criteria for the label. In order to combat this, I’ve designed my label strategy so that I understand what my label is trying to communicate and I ensure that the positive label (i.e., this ticket matches that criteria) has an opposite label, denoting that it doesn’t meat that criteria. For example, a label that I want all my tickets to have is whether the ticket was a PLANNED ticket, meaning the team decided when it would be done versus an UNPLANNED ticket, which had its schedule forced on us for one reason or another. Instead of just having a “PLANNED” label for those tickets, we also use an “UNPLANNED” label for the others. This way I can always know if a ticket was processed or not (for this criteria at least) because it should have one of these two labels.
Processing Tickets for Labelling
For the labels that I absolutely want to ensure every ticket has, I create filters to identify tickets that do not have those labels. For example, my planned/unplanned filter looks like this:
project = "Prod Ops Support" AND created >= startOfYear() AND (NOT labels in (UNPLANNED, PLANNED, TEST-TICKET) OR labels is EMPTY)This will give me a list of tickets that haven’t been labeled yet. Using the Bulk Change tool, I can quickly scan through the tickets and “check” the items that I considered UNPLANNED. With the Bulk Change Tool I can then select each ticket that I want to add the label to.
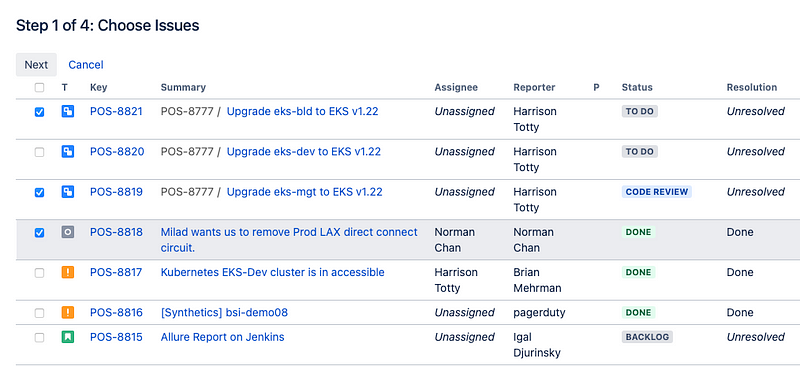
JIRA Bulk Edit Tool After going through the Bulk Edit wizard and adding the label the query should now return fewer results, since we’ve updated all of the UNPLANNED tickets. Now we can select all of the remaining tickets and add the PLANNED label to them. Repeat the same process with the Bulk Change tool and you’re good to go.
NOTE: Make sure you disable notifications for your bulk edit change. Or lots of people will be frustrated with you
I repeat this process for all label sets that I want to add. Each label set has a query similar to the one I used for PLANNED/UNPLANNED tickets which allows me to quickly identify tickets that need to be processed.
Another label pair I add is TOIL/VALUEADD. This identifies which tickets are work that we shouldn’t be doing as a team and need to automate or transition to another group. An example of TOIL work would be user creation.
All of this might sound like a lot of work, but I assure you I spend no more than 15 minutes per week doing this type of labeling work. I do it on Monday mornings every week in order to keep the volume relatively low. And again, the aim for me isn’t 100% accuracy, but to get the broad strokes so that I can see the signal start to bubble up.
Wrap Up
Now that I’ve explained my ticket types as well as my labeling process we can discuss the different types of dashboards that can be built in a future blog post.
-
Change is Scary, Even When It’s Fun
Change is Scary, Even When It’s Fun
Second-order thinking can help us evaluate the consequences of our consequences

Woman walking in front of a sign that reads Let’s change One thing I’ve learned since having children is just how early in life many of the faults in humanity show up. Children are reflections of ourselves but in the purest form. When children reveal behaviors like greed, biases and violence, it makes you start to view these behaviors as a natural part of human nature that can only be controlled through societal norms.
I say these things to prepare you for the fact that you are not immune to these behaviors. None of us are immune to biases and it’s easy to accept the reality our biases create. Biases can also hide our true motivation for taking (or not taking) a course of action.
My children are at the age where we can play video games together, which is way better than playing with Paw Patrol action figures. The artificial world of video games is starting to reveal the dark underbelly of human behavior. When I see this darkness manifest in my children, it makes me look at these behaviors critically. In this post I’ll talk about an experience I shared with my daughter Ella, who is 10 years old, and the parallels I see in the workplace.
The Video Game
Satisfactory is a video game where players work together to extract resources from an alien planet and build various components out of those resources for their employer FICSIT. To do this the players move through a series of improving capabilities and skills that allow them to build factories to automate a lot of this work. Factories are a collection of machines that automate tasks in a pipeline like fashion to start with one type of input (e.g. iron ore) and at the end of the pipeline have a type of output, like iron rods.
One of the key tasks early in the game is making fuel for your generators. Generators are used to power the other components of your factory. My daughter Ella’s very first factory was created to produce Bio Fuel , which is the most efficient type of fuel in the early stage of the game. In order to make bio fuel, Ella created a factory pipeline that would take leaves and grass, convert that into bio mass and then take the bio mass and convert that into bio fuel.
When she built the factory, she had the idea of keeping 50% of her bio mass as-is and storing it, and then sending 50% of the biomass down the pipeline to be converted to bio fuel. Early on this technique made sense but over time we realized that anything that would take bio mass as a fuel source, would also take bio fuel as a fuel source. The difference is that bio mass burns a lot faster, so a generator might consume 18 units of bio mass per minute, but would only consume 4 units of bio fuel per minute for the same power output.
Recommending change to the way things are done
Once I realized that bio fuel could be used in everything, I suggested to Ella that we just focus her factory on creating bio fuel instead of storing 50% of our bio mass as is. With many different factories running, you can spend a lot of time making sure your generators are fueled. Having to fuel them less often is a huge productivity boost for your game play. To my surprise, Ella was very resistant to the idea. Like any proposed change in any setting, Ella had a laundry list of defenses for why things should remain the same.
“We might need bio mass later in the game” was her first retort. A fair one for someone not familiar with these types of gameplay loops. But I leaned on my 20+ years of experience playing these types of games to try to rationalize with her why this isn’t likely. I explained how the game play progression typically has us moving forward and that it wouldn’t be long before we probably wouldn’t be using bio fuel either. And bio mass is so easy to acquire that it wouldn’t be a problem if we needed to build a new factory later. But sometimes experience isn’t convincing to people.
“But there’s no downside to us just storing it” came next from her. That’s true, except it’s horribly inefficient. We almost never opt for bio mass, unless we’re out of bio fuel. And often what would happen is the storage container we used to store the bio mass would fill up, which would force us to convert it to bio fuel anyways to make space in the container. But this was a manual process, so again it hit our productivity and the productivity of the factory as a whole. Inefficiency though can get so embedded in the process that people just live with it because it seems easier than the alternative.
“Bio mass is just as good as bio fuel.” Here’s a scenario where data I thought would surely win the day. As I mentioned earlier, the game tells us the burn rate of fuel types. Bio mass burns 18 units per minute while bio fuel burns 4 units per minute. Each generator can accept a stack of 200 of either fuel type. Doing the math means we need to refill bio fuel generators every 50 minutes, but bio mass generators roughly every 11 minutes. I thought the data would make this an easy conversation, but if you work in any office setting, you probably already know where this is going.
“I don’t know if that data is right.” Now she challenges the validity of the data provided by the video game developers. I don’t know if she’s thinking there’s a global conspiracy against the bio mass industry or if the developer is staffed by activists pushing an agenda. She claims that when she watched the burner it felt like they burned around the same amount of time. Now I’m starting to lose my patience a little bit.
“I just don’t think it’s worth changing the entire factory for this.” We’re finally getting to the root of the issue now! She just doesn’t feel like doing the work. I don’t think the work is actually that much but I’m a bit more experienced than she is so I can see how she might think it’s a bigger task. I offer to do it for her. Finally the last wall of resistance crumbles. She agrees to the change and decides she’ll implement it as soon as she finishes a few high priority factory tasks, ironically one of which is refueling a bunch of bio mass burning generators.
Implementing the change
Ella implemented the change in the most efficient manner possible. The conveyor belt that carries the bio mass goes into a conveyor belt splitter, sending half the bio mass to storage and half the bio mass to be created into bio fuel. She opted to just delete the conveyor belt that would have shipped the bio mass into a storage container. One minor tweak and suddenly the reality we were fighting about had finally come to fruition. We’re only producing bio fuel and we’re producing it at a much higher rate because the delivery of bio mass is now 50% faster. (Since we’re no longer splitting it)
If you’ve been reading this from the perspective of an employee at a company, a lot of this probably resonates with you. Remove video games and replace it with whatever it is your company does, and you’ve probably had a lot of these very same conversations with co-workers. And it’s easy to assign laziness, ambivalence, lack of empathy or any other host of adjectives to describe that co-workers work ethic.
The case with my daughter is the ideal scenario. The entire exercise was one of fun and recreation. The work that needed to be done was literally part of the game loop, the very thing that makes the game fun. The task was completely owned by Ella from beginning to end, so she could implement it any way she wanted. Despite all these things going for it, resistance still crept in. Why? Because it’s not the work, it’s the change.
Change is a funny thing for some people. It brings in uncertainty and doubt for the future. The devil you know versus the devil you don’t. Dealing with the inefficiencies of the current factory was a lot easier for Ella to get her head around than the potential problems that could be created by redesigning the factory from the ground up. What if she ran out of materials during the rebuild? What if she couldn’t get the pieces lined up properly? What if we ran out of fuel in our generators while the fuel factory was being rebuilt? I’m sure all these things were swirling in her mind at a subconscious level, which then consciously manifested themselves as resistance to change, with a set of adopted biases to justify that change. Confirmation bias is what happens when we interpret information in a way that confirms or supports a set of prior held beliefs. It’s what allowed Ella to replace hard data with her general feeling of how fast fuel burned. Keeping an eye out for when we might fall victim to confirmation bias is a part of being “data driven”. I put that in quotes because many people and organizations are “data driven as long as it supports what I wanted to do anyway”, which isn’t exactly the same thing. Confirmation bias plays a huge part in that mindset.
Chesterton’s Fence
Another observation I had made was how the factory was left in this modified state that might not make a ton of sense to the next set of factory workers. With the intent of the factory going from making bio mass and bio fuel, to just making bio fuel, many of the components of the factory don’t serve a functional purpose any more. We have a conveyor belt splitter that doesn’t split to anything. We have a storage container that isn’t connected to the factory at all any more. We have an extra storage container in the pipeline that doesn’t make sense with just a single fuel type being produced. If I were a new employee at this factory, I’d be a little baffled as to why these things exist. This made me think of Chesterton’s Fence and how it plays in our comfort levels when making changes.
Chesterton’s Fence is a concept of second order thinking where we not only think about the consequences of our decisions, but the consequences of those consequences. The phrase comes from the book The Thing by G.K. Chesterton. In the book, a character sees a fence but fails to see why it exists. Before removing the fence he must first understand why it was there in the first place.
As a new factory worker who is trying to make the fuel factory more efficient, I might be confused by these extra components scattered about the system. What if they had a purpose that I’m unaware of? What would removing these things from the system do? Their uselessness seems so obvious that it almost makes it even more daunting of a task to remove it because you have no idea why it exists.
This is a common problem we see with hastily implemented changes. The change is designed to deliver the value needed now as quickly as possible but sometimes at the expense of clarity for future operators of the system. Thinking about the consequences of our consequences can create a more sustainable future but at the same time, put more work on our plates in the present.
Wrap up
This post ended up going on way longer than I expected and if you’ve reached the end you deserve a cookie or a smart tart or something. The parallels in behavior between my video game-playing daughter and senior people in large organizations is startling. The truth is these behaviors are our default state of mind. Only with the awareness of our faults can we improve.
Some key takeaways from this lesson for me are:
- Biases exist early on in life and you’re not immune to them.
- Keep an eye out for confirmation bias. It can make you believe some crazy stuff
- People fear change, even in the most optimal of situations.
- Second-order thinking can help us evaluate the consequences of our consequences. It also pressures us to understand the intent behind something before we go about changing it.
This post was a bit off the beaten path but seeing these behaviors in my daughter, whom I love and is perfect, gives me room for critical thought about humans in the work force.
-
Organizing Tickets for OPS Teams
Organizing Tickets for OPS Teams — Part 1
Ticket management is one of those boring topics that comes up every now and again in OPS circles. A lot of teams that I’ve chatted with try to model their ticket management process after the development process using Sprints/Scrum. I’ve found Scrum to be limiting in an Operations setting. The amount of uninterrupted work that comes into the queue for OPS teams makes it imperative that your workflow accommodates and expects unplanned work. In this first of several posts, I’ll talk about how my team manages their work.
I should start with a little sales job on why you need tickets. It goes beyond just tracking your work. It’s about making your work visible to you and your team, but also to others around you who have a vested interest in what you’re working on and also when you intend to work on it. A Kanban Board can help to organize and communicate what the team is currently focused on. There are plenty of great posts about how Kanban works and its goals, so I won’t dive too deep into that. I’ll just highlight a few key points.
- Limit the Work in Process (WIP) at any one time
- Make sure all work is visible and has a ticket associated with it
- Work should flow left-to-right through the process
Limiting Work in Process
One of the key tenants of Kanban is to make sure you’re limiting the amount of work in process at any one time. The knee jerk reaction is to pull in more work to increase throughput of the team but it’s counterproductive. Little’s Law speaks to this particular phenomenon well. The best way I’ve found to limit WIP is to limit how many tickets each person can have in process at any one time.
For my team, we’ve opted for a maximum of two tickets per person in process. This allows engineers to hop between the tickets in the event their other tickets is blocked and it’s beyond the engineer’s ability to unblock it. This limit also helps us to gauge how many tickets we can handle at any one time in the input queue. (More on that later)
The Backlog
Like SCRUM/Sprints, Kanban workflows have the concept of a backlog. The backlog is a queue of work that you may or may not deliver. When it comes to the backlog, there are no firm commitments.
I’ve seen some Kanban boards where the Backlog is the left-most column on the Kanban board. Personally, I prefer not to display the Backlog at all on the Kanban Board, saving it for a separate board. The reason is that humans have short attention spans.
I want my team laser focused on the things that are in the input queue, because those are the things we’ve given priority to as a team. With the backlog visible, it’s too easy to see a ticket that someone thinks is important or should pop into the work queue right away. The problem with this self-prioritization? Something else stops getting worked on. I know we all believe that multi-tasking is a thing, but it’s not. This leads to missed commitments, more work in the queue than is necessary and confusion from your stakeholders as certain items seem to jump the line without explanation. (Mainly the work engineers prefer to work on) Removing the backlog from the primary working Kanban board helps to stop this from happening.
Another benefit to hiding the backlog is the amount of noise it reduces. Backlogs always grow. Even a well-groomed backlog can be intimidating to teams. You don’t want the crushing weight of expectations constantly in the face of the team. There’s no sense of progress when you see an ever growing queue to the left of your screen. Just think of your own personal to-do system and you’ll get that feeling of dread creeping over you. Protect your team from that feeling. Hide your backlog.
Prioritizing the Backlog
Now that I’ve safely hidden the backlog, my next step is to prioritize it. In my current role we use JIRA for ticket management which allows me to easily order the tickets in the backlog visually. The order updates a ranking value on the ticket which is how Jira keeps track of priority internally. Keeping the backlog ordered by priority makes it easy to select what gets worked on next. Of course priorities can change daily, so there’s a level of discipline that has to be enacted to keep the ordering honest and up-to-date. I prefer that new tickets get added to the bottom of the priorities list, which makes it incumbent on me to re-prioritize the ticket if deemed necessary. If tickets don’t automatically go to the bottom of the priority queue, you’ll find yourself in a last-in first-out queue setup, which will eventually starve all of your older tickets.
The Input Queue
With the backlog safely tucked away and prioritized, the input queue becomes the left-most column on our Kanban Board. The input queue holds all of the tickets that we’ve currently committed to for this iteration. What’s an iteration? For our team, an iteration is the cycle to which we make fresh commitments on new tickets. Every week, we try to commit to a new round of tickets to bring our input queue back to its maximum capacity. If we agree that we’ll commit to 10 tickets per week, at the end of the week we’ll replenish the input queue to get it back to 10. (Or sooner if we run out of tickets)
If you do a good job of keeping your backlog prioritized then it becomes really easy to populate the queue by just taking the top X number of tickets in the backlog and moving them to the input queue. Following this pattern, your input queue should also be ordered by priority. (There are several scenarios where that might not be true, which I will address in a subsequent post) Now your team members can begin pulling tickets from the top of the queue and beginning work on them.
The Columns
Each Kanban board has at minimum 3 columns that represent the phase work is in. They roughly fall into the category of
- To Do
- In Progress
- Done
For simple boards that might be all you need. For me I like to have a little bit more information about where a ticket is in the workflow. More columns means a better idea of where tickets might be bottlenecking when the team starts to slow down. But the more columns there are the more of a burden it can put on the team as they try to figure out the minutiae of where a task is. Unless there’s clear value in the column, avoid getting too detailed in the phases of a ticket. For my team we have the following columns.
- To Do
- In Progress
- Waiting For
- Needs PR Approval
- QA/Verification
- Done
The titles of these categories are pretty self-explanatory except for maybe “Waiting For”. This column is for tickets that are waiting on some sort of external information, time or action. For example, if we’re waiting for Saturday night because that’s when the approved maintenance window is, there isn’t much that the engineer can do to move time forward. The ticket gets moved to the Waiting For column until we can implement the change. (I could probably eliminate the Waiting For Column in favor of a flag status to indicate the ticket is blocked. More on that later)
Tickets will generally flow left-to-right on this Kanban board, showing progression towards being complete. Each phase is important (for my reporting anyway) with regard to where the ticket is in the process and how I can be of assistance. Do I need to wrangle people to get the PR approved? Is a ticket blocked waiting for someone to respond to an email? Has the change been released and we need another team to sign-off saying it’s complete? This flow gives me insight into where we’re at.
Something to keep in mind when you’re designing your workflow. You have to think about the data that you want out of the system, including reports you intend to run. That will ultimately drive how you structure your system. If you don’t intend on reporting or leveraging a status, then in my opinion there’s really no need to have a separate status. Each of these categories I’ve listed above were created to express something I wanted to be able to report on or have a quick status of. This applies to everything in your ticketing system, not just statuses. Labels, ticket types, components, tags, all these things should be driven from some sort of reporting you intend to do.
Wrap Up
When I set off writing this I thought I’d get it all done in a single blog post. But this will clearly be something I need to write about over several blog posts. In my next post I’ll discuss the various issue types I use as well as additional swim lanes that can help to add context to tickets.
-
Ask the wrong people, you build the wrong thing
Ask the wrong people and you build the wrong thing
Not long ago my wife and I received an email from our kid’s school. (They attend a CPS school.) The email was a survey of some sort that would be used to make decisions about curriculum in next year’s school program. It always excites me when parents, teachers and administrators get to collaborate on school programs.
You can imagine my frustration as I clicked on the link to the survey and was greeted with some cryptic error message from Google Forms. I wish I could remember what the error said but even as someone with a technical background, the error didn’t point to any specific action that could be taken to resolve it. Thanks to the pandemic, I’m well equipped with handling the idiosyncrasies of CPS’ implemenation of Google Apps. I logged out of all my Google accounts and then logged back in with my daughter’s CPS email address and I was granted access to the survey.
The question being asked was if we would prefer more STEM classes or more Arts related classes for extra curriculur items next year. I quickly suspected that this was probably going to lead to a case of Selection Bias as the number of people who figured out how to participate in the survey are probably more technical leaning than those that just gave up. Out of curiosity I asked a few people in my circle. The people who I’d consider technical, poked around and figured things out, while other people just gave up, assuming that there was something broken on the site, which was a fair assumption given the generic nature of the error message.
This experience got me thinking about how often we make “educated” decisions based on poor information. CPS could think that they were implementing the wishes of their student community only to find out they were addressing a subset. I’ve fallen victim to this mistake myself when I wasn’t
When my team and I were designing our infrastructure platform at Basis we had a tendency to talk to the loudest developers in the room. Those developers had very specific needs and requirements. But we failed a lesson that I’m sure every product manager in the world knows. The loudest people aren’t always representative of the larger user body. This is exactly what we encountered as we built out our chat bot. Using feedback from the noisy developers pushed us towards a model where there were many different options for building environments and packages. Instead of creating a tight streamlined process, we created different avenues for people to build and manage their environments. We supported custom datasets that were seldom used. We created different methods of creating environments, so maybe you only needed the database server or maybe you only wanted the database server and the jobs server. This created headaches for the people that didn’t want that functionality, which forced us to create omnibus commands that strung together multiple commands.
I’d really like to be angry at the developers for this but the truth is the mistake was all my own. Developers, like anyone else, have different things that they’re attracted to. Some developers love to understand the stack from top to bottom and want configurability at every level. Others are wholly disinterested in infrastructure and want to just point to a repository and say “make an environment out of this”. Despite what my personal feelings are on how much or how little interest they have, the reality is you’re probably not moving them from whatever their stated position is. And even if you do, without using a very heavy hand, you’re likely to just alienate them.
The lesson learned is to make sure that you’re talking to the audience that you actually want to talk to. Who are you asking? How are you asking them? Think about how they might self-select out of your surveys or questions and see if you can mitigate that. To engage with the entire audiece means you might need multiple methods of interviewing people. Developers who respond to surveys might not be the same developers that will respond to 1-on–1 interviews. Don’t make the mistake of optimizing for a subset of your audience or user base. Put care and thought into reaching your target audience.
-
Benefits of Conferences
Benefits of Conferences

Photo of conference attendees I love meeting new people at conferences, especially when people are first time conference attendees. One of my favorite questions to ask is “What did you have to do to get approval to attend?” The question reveals a lot about their employer and the person’s direct manager.
In many organizations, conference attendance is seen as a transactional affair with only specific line items in the transaction providing any sort of intrinsic value. These organizations saddle their employees with requirements that must be met in order to attend the conference. They have note taking requirements, presentations to give when they return and required talks to attend when at the conference. These are just a few of the requirements I’ve heard in my attendance days. It can be easy to dress these requirements up as “due diligence” but in most cases I’ve come across, this level of rigor only seems to apply to conferences. What is more likely happening is that these organizations don’t see the concrete value they expect to see from attending conferences and therefore discount them. But conferences deliver an impact that can be clearly felt, despite their concrete value being difficult to calculate and put on a ledger.
The Hallway Track
Anyone who has attended a conference will tell you that the hallway track is often the most valuable part of the conference. The hallway track is the part of the conference that is unscheduled and unscripted. As people make their way from one talk to another, they inevitably bump into each other and start a conversation that slowly balloons into something larger. Sometimes the conversation is so interesting that you forgo your next talk in favor of this impromptu conversation in-between sessions.
The magic about these conversations is that they tend to take on a life of their own, bending and weaving with the desires of the participants. Something that starts as a follow up questions on distributed locking techniques can quickly evolve into questions that are deeper and more specific to your particular problem. And despite everyone’s desire to be special, conferences make you realize that most of us are solving similar sets of problems. Even if you don’t get a definitive solution out of these talks, I assure you that you’ll get a briefing on how not to solve the problem.
The hallway track has been difficult to replicate virtually. Since the onset of the pandemic, many groups have tried and found very inventive ways to imitate it, but there’s nothing quite like the real thing. Equally difficult is putting a dollar value on the track. There’s no time slot you can point at to show your boss why you want to attend. It’s something organic that evolves, but more importantly, that you have some semblance of control over. Yes your mileage may vary but that’s really the case for everything.
Introduction to new thoughts and ideas
Albert Einstein is often attributed with the quote;
“We cannot solve our problems with the same thinking we used when we created them.”
This axiom can exist within engineering groups. They get trapped into their standard way of thinking and can’t see how a different approach might work. “That would never work here” is a common retort to new ideas. But continued and expanded expansion to new ideas and their successful implementations makes people question the way they do things. Again, never be surprised by just how many people have the same problems you have. Unless you’re Facebook, Apple, Netflix or Google, many companies have the same types of problems. It’s hard to accept that you’re not a special, magical snowflake but attending a conference can force that acceptance pretty quickly.
Sometimes these new ideas and approaches to your problem are not packaged in a flashy title that draws your attention. In my experience some of the best tid bits of information come from talks that I would have never attended or watched on my own. But when I’m at a conference, there’s always a block of time that doesn’t have a talk that speaks directly to my problems. When attending a conference in person I’m more compelled to attend a random talk in that situation. It’s incredible how often that random talk pays dividends. Would I have spent 45 minutes on that talk if I just came across it on YouTube? Probably not. But broadening the scope of what I hear and attend helps with problems that are not top of mind. Better yet, you realize that some of your underlying problems are related to activities, actions or systems that you hadn’t previously considered. Exposure to people, their problems, ideas and solutions helps to expand your thinking about your own problems.
Getting your company name out in the community
You might work for a small or medium size company that just isn’t on the mind’s of technical professionals. Attending conferences (and even better, speaking at them) helps to get your company name into the tech community. With remote work opportunities continuing to grow, the number of potential prospects sky rockets with conference attendance.
In addition to socializing the company name, you’re also socializing the company’s values by the fact that you have employees in attendance! You’d be surprised how valuable that can be to potential job seekers. I’m always surprised when I’m at a DevOps Days conference and I meet someone working at a bank or a hospital, industries that I associate with old-world thinking and mentalities. But talking to those attendees and hearing that their teams are experimenting with DevOps practices, using modern technologies and work management techniques helps to change my biased view of them.
Energizing your employees
The post-conference buzz is real. Once you’ve gotten all of this new information, you’re eager to see how it can be applied to your day-to-day work. Many people come back to the office with a basket of ideas, some of them completely crazy, but many of them completely practical and achievable. As a team you’ll have to figure out which are which. With the support of management that buzz can be channelled into making real change and providing employees with immense job satisfaction as they do it.
Job satisfaction = Retention
No amount of healthy snacks, ping-pong tables and free soda can replace the joy engineers get when they can effect change.
Virtual attendance
A quick note about virtual attendance. During the pandemic conference organizers tried very hard, with varying degrees of success, to replicate the in-person conference feel virtually. But regardless of how well conference organizers do this, remote conferences can be difficult.
For starters, networking virtually can be hard. It requires a level of intentionality either on the conference organizers or as you as an attendee. Chat rooms during a conference talk are a common way of trying to generate those networking opportunities, but they can distract you from the speaker. Hanging out in chatrooms after the talk can sometimes be effective, but again just not quite the same as in person.
Another thing to consider with virtual attendance is how you attend it. Many people attend conferences virtually, but remain logged into all of their usual modes of communication for work, which effectively means, you’re working. Without a clear separation from your work duties, virtual attendance can give way to the usual pressures of the “office”.
These are just a couple of reasons why I favor in-person conferences to virtual conferences. Are virtual conferences better than nothing? Absolutely. But I caution you to not evaluate the value of conferences based solely on virtual conferences.
Wrap-up
Conferences can be a great resource for your employees to engage in the communities that they’re a part of. Networking is crucial to building relationships and knowledge and that is an activity that can be much easier to do in person.
Conferences help expose people to new ideas and new ways to solve problems other than the standard approach the company may take. When you attend conferences you quickly learn that your problems are not as unique as you thought. You’ll without a doubt run into people that have the same problems as you. You’ll probably even meet people who have tried the same solutions and can save you from a wasted journey.
Conferences also help to energize employees. You come back from a conference and you’re excited to experiment with a lot of the techniques and technologies you learned about.
If your company won’t send you to a conference, here’s a few quick tips that might help.
- Some conferences have free tickets, especially for underrepresented groups. If you’re curious about a conference but can’t attend, definitely look into this option. I’ve seen some conferences even cover hotel and air fare.
- Speaking at conferences is another way to get into the event for free. Many conferences have a public Call for Proposals (CFP) process that you can submit to. Don’t think you need some crazy, mind bending thing to give a talk about. Your personal experience, personal communication style and touch can’t be replicated and is something unique to offer. Try it out!
- Try to show the value of the conference to your management. Highlight why you want to attend the conference and some of the soft benefits beyond what watching the YouTube videos after the conference can provide. You can use some of the points highlighted in this article.
- Pay for the conference yourself. Be sure to talk to your manager and let them know that you’re willing to pay for the conference yourself if they can support you with time off and or some help with the travel expense. This technique is depends heavily on your personal situation and the size of the conference.
- Find a new job. (Seriously) I’m not suggesting you quit right now over it, but you might want to consider adding a question about conference attendance to your list of interview questions.
-
Authoring K8s Manifests
Authoring K8s Manifests

Kubernetes Logo Note: This is an internal blog post that I wrote at our company. When I interact with people in the tech community they’re often curious about how different teams approach think about these problems more broadly, so I thought I’d include this. The audience was internal Basis employees, so some of the references may not make sense.
There are no right solutions
As humans we’re obsessed with not making the wrong choice. Everything from where you go to school to whether you should order the chicken or the steak, is besieged by the weight of making “the wrong” choice. But that framing suggests that right and wrong are absolutes, as if you could plugin all the variables of a given situation and arrive at a conclusive answer. This couldn’t be further from the truth. Not in life and definitely not in engineering.
Choices are about trade-offs. Depending on what you’re optimizing for one set of trade-offs seems more practical than another. For example, investing your savings is a good idea, but the vehicles you use to invest differ based on your goals. If you need the money soon, a money market account offers flexibility but at the expense of good returns. The stock market might offer higher returns but at the risk of losing some of the principal. Do you need the money in 2 years or 20 years? How much do you need it to grow? How quickly?
The economist Thomas Sowell famously said “There are no solutions, there are only trade-offs; and you try to get the best trade-off you can get, that’s all you can hope for.”
This statement holds true in software engineering as well.
Imperative vs Declarative Manifest Authoring
When it comes to Kubernetes manifests, there really is only one method of applying those manifests and that’s using a declarative model. We tell Kubernetes what it is we want the final state to look like (via the manifests) and we rely on Kubernetes to figure out the best way to get us to that state.
With Kubernetes all roads lead to a declarative document being applied to the cluster, but how we author those manifests can take on an imperative bend if we wanted to using various template engines like Helm, Jsonnet or the now defunct Ksonnet. But using templating languages provides a power and flexibility that allows us to do some things that we probably shouldn’t do given our past experiences. Templating opens the door for impeding some of the goals we have around the Kubernetes project and what the experience we’re specifically optimizing for. I’d prefer to stay away from templating layers as much as possible and be explicit in our manifest declarations.
What are we optimizing for?
In order to really evaluate the tools we’ve got to discuss what it is we’re optimizing for. These optimizations are in part due to past experiences with infrastructure tools as well as acknowledgements of the new reality we’ll be living in with this shared responsibility model for infrastrcuture.
Easy to read manifests to increase developer involvement
With the move to Kubernetes we’re looking to get developers more involved with the infrastructure that runs their applications. There won’t be a complete migration of ownership to development teams, but we do anticipate more involvement from more people. The team that works on infrastructure now is only 6 people. The development org is over 40 people. That said the reality is that many of these developers will only look at the infrastructure side of things 4 or 5 times a year. When they do look at it, we want that code to be optimized for reading rather than writing. The manifests should be clear and easy to follow.
This will require us to violate some principles and practices like code reuse and DRY, but after years of managing infrastructure code we find that more often than not, each case requires enough customization where the number of parameters and inputs to make code actually reusable, ballons quickly and becomes a bit unwieldy. Between our goals and the realities of infrastructure code reuse, using clear and plain manifest definitions is a better choice for us. We don’t currently have the organizational discipline to be able to reject certain customizations of an RDS instance. And honestly, rejecting a customization request because we don’t have the time to modify the module/template doesn’t feel like a satisfying path forward.
A single deployment tool usable outside the cluster
Because of the application awareness our current orchestration code has, we end up with multiple deployment code bases that are all fronted by a common interface. (Marvin, the chatbot) Even with Marvin serving as an abstraction layer, you can see chinks in the facade as different deployment commands have slightly different syntax and or feature support. In the Kubernetes world we want to rely on a single deploy tool that tries to keep things as basic as
kubectl applywhen possible. Keeping the deploy tool as basic as possible will hopefully allow us to leverage the same tool in local development environments. In order to achieve this goal, we’ll need to standardize on how manifests are provided to the deployment tool.There is a caveat to this however. The goal of a single method to appply manifests is separate and distinct from how the manifests are authored. One could theoretically use a template tool like Helm to write the manifests in, but then provide the final output to the deploy tool. This would violate another goal of easy to read manifests. I just wanted to call out it could be done. Having some dynamic preprocessor that happens ahead of the deploy tool and commits the final version of the manifest to the application repository could be a feasible solution.
Avoiding lots of runtime parameters
Another issue that we see in today’s infrastructure is that our deploy tool requires quite a bit of runtime information. A lot of this runtime information happens under the hood, so while the user isn’t required to provide it, Marvin infers a lot of information based on what the user does provide. For example, when a user provides the name “staging0x” as the environment, Marvin then recognizes that he needs to switch to the production account vs the preproduction account. He knows there’s a separate set of Consul servers that need to be used. He knows the name of the VPC that it needs to be created in as well as the Class definition of the architecture. (Class definitions are our way to scope the sizing requirements of the environment. So a class of “production” would give you one sizing and count of infrastructure, while a class of “integration” or “demo” will give you another)
This becomes problematic when we’re troubleshooting things in the environment. For example, if you want to manually run
terraform applyor even aterraform destroy, many times you have to look at previously run commands to get a sense what some of the required values are. In some cases, like during a period of terraform upgrading, you might need to know precisely what was provided at runtime for the environment in order to continue to properly manage the infrastructure. This has definitely complicated the upgrades of components that are long lived, especially areas where state is stored. (Databases and Elasticache for example)Much of the need for this comes from the technical debt incurred when we attempted to create reusable modules for various components. Each reusable module would create a sort of bubble effect, where input parameters for a module at level 3 in the stack would necessitate that we ask for that value at level 1 so that we can propagate it down. As we added support for a new parameter to support a specific use case, it would have the potential to impact all of the other pieces that use it. (Some of this is caused by limitations of the HCL language that Terraform uses)
Nevertheless, when we use templating tools we open the door for code reuse as well as levels of inference that makes the manifest harder to read. (I acknowledge that putting “code reuse” into a negative context seems odd) This code reuse in particular though tends to be the genesis of parameterization that ultimately bubbles its way up the stack. Perhaps not on day one, but by day 200 it seems almost too tempting to resist.
As an organization, we’re relatively immature as it relates to this shared responsibility model for infrastructure. A lot of the techniques that could mitigate my concerns haven’t been battle tested in the company. After some time of running in this environment and getting use to developer and operations interactions my stance may soften on this, but for day one it is a little bit too much to add additional processes to circumvent the short comings.
Easily repeated environment creation
In our internal infrastructure as code (IaC) testing we would often have a situation where coordinating infrastructure changes that needed to be coupled with code changes was a bit of a disaster. Terraform would be versioned in one repository, but SaltStack code would be versioned in a different repository, but the two changes would need to be tested together. This required either a lot of coordination or a ton of manual test environment setup. To deal with the issue more long-term we started to include a branch parameter on all environment creation commands, so that you could specify a custom SaltStack server, a specific Terraform branch and a specific SaltStack branch. The catch was you had to ensure that these parameters were enacted all the way down the pipeline. The complexity that this created is one of the reasons I’ve been leaning towards having the infrastructure code and the application code exist in the same repository.
Having the two together also allows us to hardcode information to ensure that when we deploy a branch, we’re getting a matching set of IaC and application code by setting the image tag in the manifest to match the image built. (There are definite implementation details to work out on this) This avoids the issue of infrastructure code being written for the expectations of version 3.0 of application code, but then suddenly being provided with version 2.0 of application code and things breaking.
We see this when we’re upgrading core components that are defined at the infrastructure layer or when we role out new application environment requirements, like AuthDB. When AuthDB rolled out, it required new infrastructure, but only for versions of the software that were built off the AuthDB branch. It resulted in us spinning up AuthDB infrastructure whether you needed it or not, prolonging and sometimes breaking the creation process for environments that didn’t need AuthDB.
Assuming we can get over a few implementation hurdles, this is a worthwhile goal. It will create a few headaches for sure. How do we make a small infrastructure change in an emergency (like replicacount) without triggering an entire CI build process? How do we ensure OPS is involved with changes to the /infrastructure directory? All things we’ll need to solve for.
Using Kustomize Exclusively
The mixture of goals and philosophies has landed us on using Kustomize exclusively in the environment. Along with that we’d like to adopt many of the Kustomize philosophies around templating, versioning and their approach to manifest management.
While Helm has become a popular method for packaging Kubernetes applications, we’ve avoided authoring helm charts in order to minimize not just the tools, but also the number of philosophies at work in the environment. By using Kustomize exclusively, we acknowledge that some things will be incredibly easy and some things will be incredibly more difficult than they need to be. But that trade-off is part of adhering to an ideology consistently. Some of those tradeoffs are established in the Kubernetes team’s Eschewed Features document. Again, this isn’t to say one approach is right and one is wrong. The folks at Helm are serving the needs of many operators. But the Kustomize approach aligns more closely with the ProdOps worldview of running infrastructure.
We’re looking to leverage Kustomize so that we:
- Don’t require preprocessing of manifests outside of the Kustomize commands
- Being as explicit as possible in manifest definitions, making it easy for people who aren’t in the code base often, to read it and get up to speed.
- Being able to easily recreate environments without the need for storing or remembering run time parameters that were passed.
- Minimizing the number of tools used in the deployment pipeline
I’m not saying it’s the right choice. But for ProdOps it’s the preferred choice. Some pain will definitely follow.
-
Organizing your todos for better effectiveness
Organizing your todos for better effectiveness
If I’ve learned anything during the pandemic it’s this; time is not my constraining resource. The lockdown has forcibly removed many of the demands on my time that I’ve conveniently used as an excuse. My 35-minute commute each way is gone. My evening social commitments have all evaporated. Time spent shuffling kids between extra curricular activities has now become a Zoom login. What am I doing with all of this extra time?
After a few work days that felt incredibly productive, I decided to deeply examine what made those days more effective than others. I didn’t necessarily accomplish more. I spent most of the time doing a rewrite of some deployment code. At the end of the day I had a bunch of functions and unit tests written, but I didn’t have anything impactful to share just yet. That’s when I realized it wasn’t the deliverable of a task that made me feel productive but the level of purpose with which I worked.
What was it about those days that made me feel so unproductive? The one thing they all had in common was a heavy sense of interruption. Sometimes the interruptions were driven by the meetings that seem to invade my calendar, spreading like a liquid to fill every available slice of time. Other times it was the demands of my parallel full time job as a parent/teacher/daycare provider, now that my kids are permanently trapped inside with me. The consistent theme was that when I only had 30 minutes of time, it seemed impractical to work on a task named “Rewrite the deployment pipeline”. My problem consisted of two major issues, the size of the work and how the work was presented to me.
We tend to think of tasks in terms of a deliverable. A large task gets unfairly summarized as a single item, when in fact, it’s many smaller items. I learned this quite some time ago but the issue still shows up in my task list from time to time. The first step was to make sure that my tasks were broken down into chunks that could be accomplished in a maximum of 30 to 60 minutes. Breaking down “Rewrite the deployment pipeline”, could be separated into tasks like:
- Write unit tests for the metadata retrieval function
- Write the metadata retrieval function
- Move common functions into a standard library
- Update references of the common functions to the new standard library
You get the idea. These are all small tasks that I should be able to tackle in a 60 minute period.
The more pressing issue that I would encounter however is presenting work based on the current work context that I’m in. If I’ve only got 15 minutes before my next meeting, it takes a lot of energy to start to get into a task that I know I can’t finish in that period. Because I didn’t have time to finish any of the items on my important list, I’d decide to play hero and go looking in Slack channels to see whose questions I could answer. But for some reason at the end of the week when I review my list of tasks, I’d still have all these small tasks that I hadn’t made any progress on.
This is where Omnifocus’s perspectives functionality saves me. Perspectives allow me to look at tasks that meet a specific criteria. I have a perspective I use called “Focus” that shows me which tasks I’ve flagged as important and which tasks are “due” soon. (In my system, due means that I’ve made an external commitment to a date or there is some other time based constraint on the task)
While this is great to make sure that I’m on top of things that I’ve made commitments to, it doesn’t do a great job of showing me what I can actually work on given the circumstances. There’s no indication of how much time a task will take. Having a separate category for phone calls is great when I’m in phone calling mode. But there’s different level of time commitments between “Call Mom and make sure she got the gift” and “Call your mortgage broker to discuss refinancing options”. I needed a way to also distinguish those tasks from each other.
Awhile ago I had started leveraging an additional context/tag of “Short Dashes” and “Full Focus”. This was just a quick hint of how much energy was required for the task. But by using those contexts/tags, I can create a new filter that highlighted short dash items that I could do between meetings. And now that Omnifocus supports multiple tags, I can also add a tag based on the tool that I need to complete the task. (e.g. Email, Phone, Computer, Research)
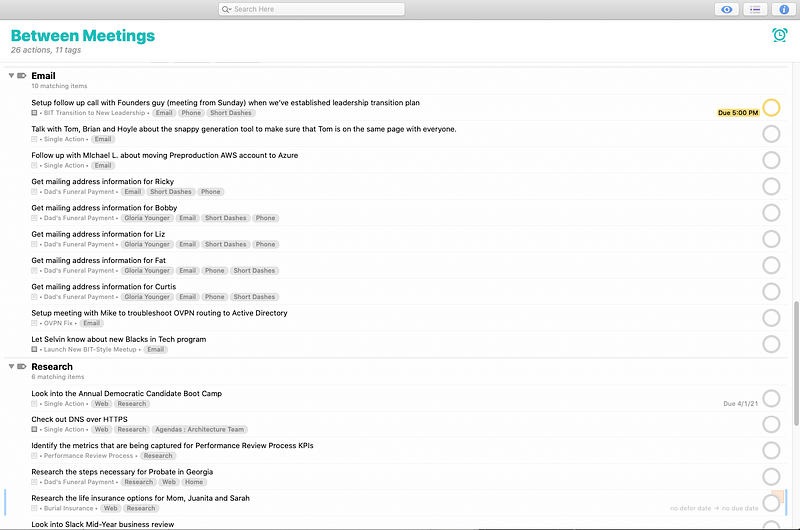
Now when I have a short amount of time, I can quickly flip to this perspective of work, which allows me to wrap up a lot of the smaller tasks that I need to do. This helps me to maximize those few minutes that I would normally waste checking Twitter because I didn’t have enough time to complete a larger task.
Another common scenario I’d run into was where my physical presence was tied up, but my mind was free. (Think of waiting for a doctor’s appointment to start. Back when we did those crazy things) I created a mobile perspective specifically for that purpose! It looks at all the tasks that I could complete on a mobile device.
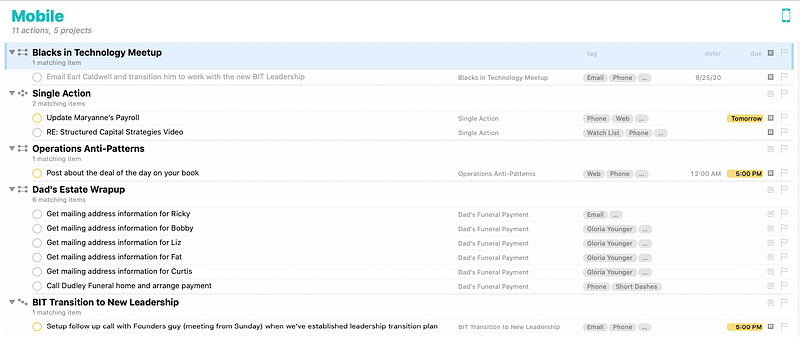
These small changes have helped me to become more effective in those smaller slices of time. Now I know what I can make progress on regardless of my situation and begin to make some of that extra time I’ve got useful.
If you don’t have a to do management system, I’d highly recommend Omnifocus and reading the book Getting Things Done by David Allen.
-
ChatOps/ChatBots at Centro
ChatOps/ChatBot at Centro
“white robot action toy” by Franck V. on Unsplash During DevOpsDays PDX I chatted with a number of people who were interested in doing ChatOps in their organizations. It was the motivation I needed to take this half-written blog post and put the finishing touches on it.
Why a ChatBot?
The team at Centro had always flirted with the idea of doing a chatbot, but we stumbled into it to be honest, which will account for a bunch of the problems we’ve encountered down the road. When we were building out our AWS Infrastructure, we had envisioned an Infrastructure OPS site that would allow users to self-service requests. A chatbot seemed like a novelty side project. One day we were spit-balling on what a chatbot would look like. I mentioned a tool I had been eyeing for a while called StackStorm. StackStorm has positioned itself as an “Event-Driven Automation” tool, the idea being that an event in your infrastructure could trigger an automation workflow. (Auto-remediation anyone?) The idea seemed solid based on the team’s previous experience at other companies. You always find that you have some nagging problem that’s going to take time to get prioritized and fixed. The tool also had a ChatOps component, since when you think about it, a chat message is just another type of event.
To make a long story short, one of our team members did a spike on StackStorm out of curiosity and in very short order had a functioning ChatBot ready to accept commands and execute them. We built a few commands for Marvin (our chatbot) with StackStorm and we instantly fell in love. Key benefits.
- Slack is a client you can use anywhere. The more automation you put in your chatbot the more freedom you have to truly work anywhere.
- The chatbot serves as a training tool. People can search through history to see how a particular action is done.
- The chatbot (if you let it) can be self-empowering for your developers
- Unifies context. (again if you let it) The chatbot can be where Ops/Devs/DBAs all use the same tool to get work done. There’s a shared pain, a shared set of responsibility and a shared understanding of how things are operated in the system. The deploy to production looks the same way as the deploy to testing.
Once you get a taste for automating workflows, every request will go under the microscope with a simple question; “Why am I doing this, instead of the developer asking a computer to do it”.
Chatbot setup
StackStorm is at the heart of our chatbot deployment. The tool gave us everything we needed to start writing commands. The project ships with Hubot but unless you run into problems, you don’t need to know anything about Hubot itself. The StackStorm setup has a chatops tutorial to get into the specifics of how to set it up.
The StackStorm tool consists of various workflows that you create. It uses the Mistral workflow engine from the OpenStack Project. It allows you to tie together individual steps to create a larger workflow. It has the ability to launch separate branches of the workflow as well, creating some parallel execution capabilities. For example, if your workflow depends on seeding data in two separate databases, you could parallelize those tasks and then have the workflow continue (or “join” in StackStorm parlance) after those two separately executing tasks complete. It can be a powerhouse option and a pain in the ass at the same time. But we’ll get into that more later in the post.
The workflows are then connected to StackStorm actions, which allow you to execute them using the command line tool or the Chatbot. An action definition is a YAML file that looks like
---
name: "create"
pack: platform
runner_type: "mistral-v2"
description: "Creates a Centro Platform environment"
entry_point: "workflows/create.yaml"
enabled: true
parameters:
environment:
type: "string"
required: true
description: "The name of the environment"
requested_version:
type: "string"
default: "latest"
description: "The version of the platform to deploy"Workflows and actions are packaged together in StackStorm via “packs”. Think of it as a package in StackStorm that provides related functionality to a product. For us, we group our packs around applications, along with a few shared libraries for actions we perform from multiple packs. The above action is from the platform pack, which controls management of our primary platform environment. There are a bunch of community supported packs available via the StackStorm Exchange.
Then to finally make this a chat command, we define an alias. The alias identifies what messages in chat will trigger the associated action.
---
name: "create"
action_ref: "platform.create"
description: "Creates a Platform environment"
formats:
- "create platform environment named {{ environment }}( with dataset {{ dataset }})?( with version {{ requested_version='latest' }})"
ack:
format: "Creating platform environment {{ execution.parameters.environment }}"
append_url: false
result:
format: "Your requested workflow is complete."The formats section of the alias is a slightly modified regular expression. It can be a bit difficult to parse at times as commands become more complex with more optional parameters. The {{ environment }} notation expresses a parameter that will be passed on to the associated action. You can also set that parameter to a default value via assignment, as in {{ requested_version=latest }}. This means if a user doesn’t specify a requested_version, “latest” will be passed as the value for that parameter. Between regex and default parameters, you can have a lot of control over parameters that a user can specify. You can also have multiple formats that trigger the same action. You can see what action this will be invoked by the action_ref line. It’s in a pack.action_name format.
StackStorm brings a lot to the table
This might seem like a lot to get setup per command, but it’s actually quite nice to have StackStorm as this layer of abstraction. Because StackStorm is really an event-automation tool, it exposes these workflows you create in 3 different ways.
- The chatbot allows you to execute commands via your chat tool. Hubot supports a number of chat tools, which I believes translates to StackStorm support as well.
- The packs and actions you create can be executed from the StackStorm run command manually. This is extremely useful when there’s a Slack outage. The command syntax is
st2 run platform.create environment=testing requested_version=4.3And just like in chat, optional parameters will get default values. - The StackStorm application also provides API access. This gives you the ability to call workflows from just about any other application. This is great when someone needs to do the exact same thing a user might do themselves via the Chatbot. That whole shared context thing showing up again.
What do you run via Chatbot?
To put it simply, as much as we can. Anytime there’s a request to do something more than once, we start to ask ourselves, “Are we adding value to this process or are we just gate keepers?” If we’re not adding value, we put it in a chat command. Some examples of things we have our.
- Create an environment
- Restore an environment
- Take a DB Snapshot of an environment
- Scale nodes in an Autoscaling group
- Execute Jenkins build jobs
- Scale the Jenkins worker instance count
- Run migrations
- Pause Sidekiq
- Restart services
- Deploy code
- Put an environment in maintenance mode
- Turn on a feature toggle
- Get a config value from Consul
- Set a config value in Consul
In all, we have over 100 chat commands in our environment.
But what about Security
Yes, security is a thing. Like most things security related you need to take a layered approach. We use SSO to authenticate to Slack, so that’s the first layer. The second layer is provided inside the workflows that we create. You have to roll your own RBAC, but most organizations have some sort of Directory Service for group management. For Slack in particular the RBAC implementation can be a bit mess.y The chatbot variables you get as part of each message event include the user’s username, which is changeable by the user. So you really need to grab the user’s token, look up the user’s info with the token to get the email address of the account and then use that to look up group information in whatever your directory service is.
We also ensure that dangerous actions have other out-of-band workflow controls. For example, you can’t just deploy a branch to production. You can only deploy an RPM that’s in the GA YUM repository. In order to get a package to the GA repository, you need to build from a release branch. The artifact of the release branch gets promoted to GA, but only after the promotion confirms that the release branch has a PR that has been approved to go to master. These sorts of out-of-band checks are crucial for some sensitive actions.
Push based two-factor authentication for some actions is desired too. The push based option is preferred because you don’t want to have a two-factor code submitted via Chat, that is technically like for another 60–120 seconds. We’re currently working on this, so keep an eye out for another post.
Lastly, there are some things you simply can’t do via the Chatbot. No one can destroy certain resources in Production via Chat. Even OPS has to move to a different tool for those commands. Sometimes the risk is just too great.
Pitfalls
A few pitfalls with chatbots that we ran into.
- We didn’t define a common lexicon for command families. For example, a deploy should have very similar nomenclature everywhere. But because we didn’t define a specific structure, some command are
create platform environment named demo01and some arecreate api environment demo01. The simple omission ofnamecan trip people up who need to operate in both the platform space and the api space. - The Mistral workflow is a powerful tool, but it can be a bit cumbersome. The workflow also uses a polling mechanism to move between steps. (Step 1 completes, but step 2 doesn’t start until the polling interval occurs and the system detects step 1 finished) As a result, during heavy operations you can spend a considerable amount of time wasted with steps completing, but waiting to poll successfully before they move on.
- Share the StackStorm workflow early with all teams. Empower them to create their own commands early on in the process, before the tools become littered with special use cases that makes you hesitant to push that work out to other teams.
- Make libraries of common actions early. You can do it by creating custom packs so that you can call those actions from any pack.
- Use the mistral workflow sparingly. It’s just one type of command runner StackStorm offers. I think the preferred method of execution, especially for large workflows, is to have most of that execution in a script, so that the action becomes just executing the script. The Mistral tool is nice, but becomes extremely verbose when you start executing a lot of different steps.
Conclusion
We’re pretty happy with our Chatbot implementation. It’s not perfect by any means, but it has given us back a lot of time in wasted toil work. StackStorm has been a tremendous help. The StackStorm Slack is where a lot of the developers hangout and they’re amazing. If you’ve got a problem, they’re more than willing to roll up their sleeves and help you out.
While not in-depth, I hope this brief writeup has helped someone out there in their Chatbot journey. Feel free to ping me with any questions or leave comments here.
-
Stories vs Facts in Metrics
You need to measure your processes. It doesn’t matter what type of process, whether it be a human process, a systems process or a manufacturing process, everything needs to be measured. In my experience, you’ll often find humans resistant to metrics that measure themselves. There’s a lot of emotion that gets caught up in collecting metrics on staff because unlike computers, we intuitively understand nuance. I’ve worked hard to be able to collect metrics on staff performance while at the same time not adding to the team’s anxiety when the measuring tape comes out. A key to that is how we interpret the data we gather.
At Centro, we practice Conscious Leadership, a methodology to approaching leadership and behaviors throughout the organization. One of the core tenants of Conscious Leadership is this idea of Facts vs Stories. A fact is something that is completely objective, something that could be revealed by a video camera. For example, “Bob rubbed his forehead, slammed his fist down and left the meeting”. That account is factually accurate. Stories are interpretations of facts. “Bob got really angry about my suggestion and stormed out of the meeting.” That’s a story around the fact that Bob slammed his fist down and left the meeting, but it’s not a fact. Maybe Bob remembered he left his oven on. Maybe he realized at that exact moment the solution to a very large problem and he had to test it out. The point is, the stories we tell ourselves may not be rooted in reality, but simply a misinterpretation of the facts.
This perspective is especially pertinent with metrics. There are definitely metrics that are facts. An example is number of on-call pages to an employee. That’s a fact. The problem is when we take that fact and develop a story around it. The story we may tell ourselves about that is we have a lot of incidents in our systems. But the number of pages a person gets may not be directly correlated to the number of actual incidents that have occurred. There is always nuance there. Maybe the person kept snoozing the same alert and it was just re-firing, creating a new page.
There are however some metrics that are not facts, but merely stories in a codified form. My favorite one is automatically generated stats around Mean Time to Recovery. This is usually a metric that’s generated via means of measuring the length of an incident or incidents related to an outage. But this metric is usually a story and not a fact. The fact is the outage incident ticket was opened at noon and closed at 1:30pm. The story around that is it took us 1.5 hours to recover. But maybe the incident wasn’t closed the moment service was restored. Maybe the service interruption started long before the incident ticket was created. Just because our stories can be distilled into a metric doesn’t make them truthful or facts.
Facts versus stories is important in automated systems, but even more so when dealing with human systems and their related workflows. Looking at a report and seeing that Fred closed more tickets than Sarah is a fact. But that doesn’t prove the story that Fred is working harder than Sarah or that Sarah is somehow slacking in her responsibilities. Maybe the size and scope of Fred’s tickets were smaller than Sarah’s. Maybe Sarah had more drive-by conversations than Fred, which reduced her capacity for ticket work. Maybe Sarah spent more time mentoring co-workers in a way that didn’t warrant a ticket. Maybe Fred games the system by creating tickets for anything and everything. There are many stories we could make up around the fact that Fred closed more tickets than Sarah. It’s important as leaders that we don’t let our stories misrepresent the work of a team member.
The fear of stories that we make out of facts is what drives the angst that team members have when leaders start talking about a new performance metric. Be sure to express to your teams the difference between facts and stories. Let them know that your measurements serve as signals more than truths. If Fred is closing a considerable larger number of tickets, it’s a signal to dig into the factors of the fact. Maybe Fred is doing more than Sarah, but more than likely, the truth is more nuanced. Digging in may reveal corrective action on how work gets done or it might reveal a change in the way that metric is tracked. (And subsequently, how that fact manifests) Or it might confirm your original story.
Many people use metrics and dashboards to remove the nuance of evaluating people. It should serve as the prompt to reveal the nuance. When you take your issue to your team, make sure you are open about the fact and your story around those facts. Be sure to separate the two and have an open mind as you explore your story. The openness and candor will provide a level of comfort around the data being collected, because they know it’s not the end of the conversation.
-
How You Interview is How You Hire
“Of course you can’t use Google, this is an interview!” That was the response a friend got when he attempted to search for the syntax to something he hadn’t used in awhile in an interview. After the interview was over, he texted me and told me about the situation. My advice to him was to run as fast as he could and to not think twice about the opportunity, good or bad. I haven’t interviewed at a ton of places as a candidate, so my sample size is statistically insignificant, but it seems insane in today’s world that this would be how you interview a candidate.
As a job candidate, you should pay special attention to how your interview process goes. You spend so much time focused on getting the answers and impressing the tribunal, that you can sometimes fail to evaluate the organization based on the nature of questions being asked and how they are asked. As an organization, how you interview is how you hire, how you hire is how you perform. This is an important maxim, because it can give you, the job seeker, a lot of insight into the culture and personalities you might be working with soon.
The interview process I described earlier seems to put more emphasis on rote memorization than actual problem solving ability. Coming from someone who still regularly screws up the syntax for creating symlinks, I can atest to the idea that your ability to memorize structure has no bearing on your performance as an engineer.
What does an emphasis on memorization tell me about an organization? They may fear change. They may demand the comfort of tools they know extremely well, which on the face of it isn’t a bad thing. Why use the newest whizzbangy thing when old tied and true works? Well sometimes, the definition of “works” changes. Nagios was fine for me 20 years ago, but it isn’t the best tool for the job with the way my infrastructure looks today, regardless of how well I know Nagios. (on a side note, I think this describes VIM users. We labor to make VIM an IDE because we’ve spent so many years building up arcane knowledge, that starting over seems unpalatable. But I digress)
No one expects to work at a place where Google isn’t used extensively to solve problems. So what exactly are interviewers attempting to accomplish by banning it? Creating a power-dynamic? Seeing how you work under-pressure? You work in an environment where Internet access is heavily restricted? These goals very well could be pertinent to the job, but how you evaluate those things are just as important as the results you get from them.
I wish there was a rosetta stone for interview format to personality types, but this is just one example of the type of thing I look for when interviewing and try to actively avoid when giving an interview. Things to also look out for
- Are they looking for a specific solution to a general problem? Maybe you have an answer that works, but you feel them nudging you to a predetermined answer. (e.g. Combine two numbers to get to 6. They might be looking for 4 and 2, but 7 and –1 are also valid)
- Did the interview challenge you at all technically? Will you be the smartest person in the room if you’re hired?
- Are you allowed the tools that you would fully expect to use on the job? (Google, IDE help documentation etc)
- Are they asking questions relevant to the actual role? Preferably in the problem space you’ll be working in.
Paying attention to how a company evaluates talent gives you insight into the type of talent they have. The assumption is always that the people giving the interview have the right answers, but plenty of unqualified people have jobs and those same unqualified people often sit in on interviews.
Remember that the interview is a two-way street. Look to the interview process as a way to gleam information about all of the personalities, values and priorities that make the process what it is. And then ask yourself, is it what you’re looking for?
-
Hubris — The Interview Killer
Hubris — The Interview Killer
Interviewing engineers is a bit more art than science. Every hiring manager has that trait that they look for in a candidate. As an interviewer, you subconsciously recognize early on if the candidate has that magical quality, whatever it may be for you. It either qualifies or disqualifies a candidate in an instant. The trait that I look for to disqualify a candidate is hubris.
Self-confidence is a wonderful thing, but when self-confidence becomes excessive, it’s toxic and dangerous. That danger is never more prevalent then during the build vs buy discussion. The over-confident engineer doesn’t see complex problems, just a series of poor implementations. The over-confident engineer doesn’t see how problems can be interconnected or how use cases change. Instead they say things like “That project is too heavy. We only need this one small part” or “There aren’t any mature solutions, so we’re going to write our own.”

The cocky engineer to the rescue Humility in an engineer is not a nicety, it’s a necessity. Respect for the problem space is a required ingredient for future improvements. But as important as respect for the problem is, respect for the solutions can be even more important. Every solution comes with a collection of trade-offs. The cocky engineer doesn’t respect those trade-offs or doesn’t believe that they were necessary in the first place. The cocky-engineer lives in a world without constraints, without edge cases and with an environment frozen in time, forever unchanging.
But why does all this matter? It matters because our industry is full of bespoke solutions to already solved problems. Every time you commit code to your homegrown log-shipping tool, an engineer that solves this problem as part of their full-time job dies a little bit on the inside. Every time you have an easy implementation for leader election in a distributed system, a random single character is deleted from the Raft paper.
I’m not suggesting that problems are not worth revisiting. But a good engineer will approach the problem with a reverence for prior work. (Or maybe they’re named Linus) An arrogant engineer will trivialize the effort, over promise, under deliver and saddle the team with an albatross of code that always gets described as “some dark shit” during the on-boarding process to new hires.
If problems were easy, you wouldn’t be debating the best way to solve it because the answer would be obvious and standard. When you’re evaluating candidates, make sure you ask questions that involve trade-offs. Ask them for the flaws in their own designs. Even if they can’t identify the flaws, how they respond to the question will tell you a lot, so listen closely. If you’re not careful, you’ll end up with a homegrown Javascript framework….or worse.
-
I really like the concept here, but I’m not sure I’m fully getting it.
I really like the concept here, but I’m not sure I’m fully getting it. Adaptive Capacity *can* be pretty straight forward from a technology standpoint, especially in a cloud type of environment where the “buffer” capacity doesn’t incur cost until it’s actually needed. When it comes to the people portion, I’m not sure if I’m actually achieving the goal of “adaptive” or not.
My thought is basically building in “buffer” in terms of work capacity, but still allocating that buffer for work and using prioritization to know what to drop when you need to shift. (Much like the buffers/cache of the Linux filesystem) The team is still allocated for 40 hours worth of work, but we have mechanisms in place to re-prioritize work to take on new work. (i.e. You trade this ticket/epic for that ticket/epic or we know that this lower value work is the first to be booted out of the queue)
This sounds like adaptive capacity to me, but I’m not sure if I have the full picture, especially when I think of Dr. Cook’s list of 7 items from Poised to Deploy. The combination of those things is exactly what makes complex systems so difficult to deal with. People understand their portion, but not the system as a whole, so we’re always introducing changes/variance with unintended ripple effects. And I think that’s where it feels like I have a blindspot when it comes to the concept.
I might have jumped the gun on this post, because I still have one of the keynotes you linked in the document to watch as well as a PDF that Allspaw tweeted, but figured I’d just go ahead and get the conversation rolling before it fell off my to-do list. =)